

- 分类问题
- 假设函数(Hypothesis)的表达
- 决策边界(Decision Boundary)
- 成本函数(cost function)
- 梯度下降算法(Gradient Descent)
- 高级优化
- 多类分类问题
- 过度拟合的问题
- 带有正规化的成本函数
- 正规化线性回归
- 正规化逻辑回归
- 参考
- 所有笔记链接
分类问题
之前有提到过监督学习分为两个小类:回归和分类,直观上的区别是分类问题的解都是离散的,而之前使用的预测房屋面积的方法都是有连续的解。逻辑回归(Logistic Regression)中的二元分类问题,一般使用0表示负类(negative class),1表示正类(positive class),这个标记方式对最终的分析结果没有影响,只是习惯采用这个方式。比如对于邮件是否是垃圾邮件,1表示是,0表示不是;对于是否有恶性肿瘤,1表示是,0表示不是(说明是良性肿瘤)。
在二元分类问题中,结果集分布为{0, 1},以下面的分布作为示例说明
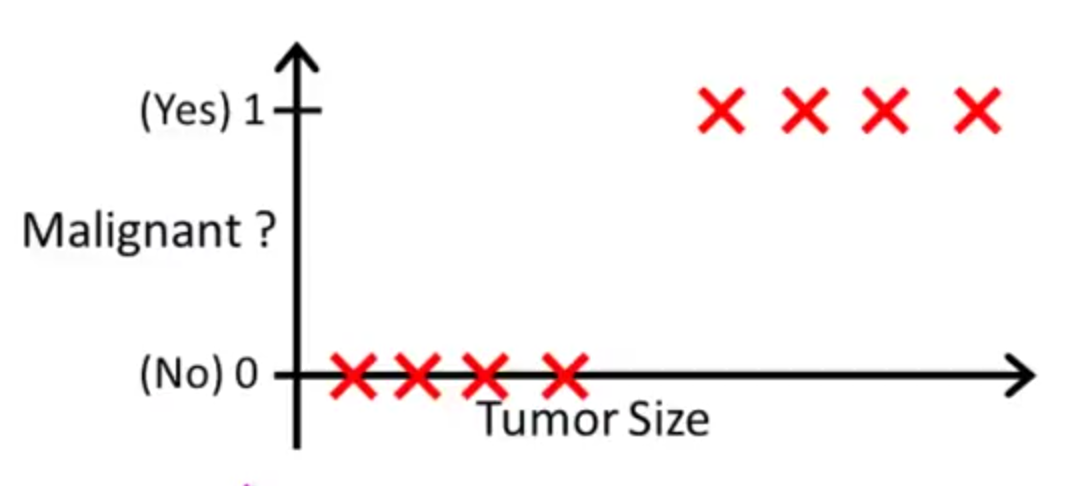
根据肿瘤的大小判断是否是恶性肿瘤,通过训练集可以发现,在某一个临界点之后,结果都为1(是恶性肿瘤),大小小于这个临界点的肿瘤都为良性的。也许通过某个线性回归的方法能构造出一个模型达到一样的效果,比如建立一个一元线性回归的模型,然后对$x \in [0, + \infty)$作预测,预测结果大于0.5的部分设置结果为1,小于0.5部分设置为0,但是这么做有两个问题。首先,对于一个比较大的x,预测值已经远远大于1了,强行把预测结果拉回1,这个与直觉不符;其次,更重要的原因是,这种方式没有办法建立一个合适的模型,比如在x很大的地方多添加了一个训练数据,这个点的y值是1,按照常理,这个训练数据的添加是不会改变原有模型的,因为跟我们的判断相同,临界点之后的值都是1,但是如果使用一元线性回归模型,会发现这个模型并不适用于这种情况,这个训练数据会导致线性模型的斜率($\theta_1$的值)减小,进一步导致临界点附近的预测值小于0.5,造成的预测结果误差比较大。所以线性回归模型并不适用于二元分类问题,这个问题需要有其他的算法。根本上的原因是这个训练集呈现的并不是一个线性的情形。
另外值得注意的是:逻辑回归(Logistic Regression)问题并不属于回归(Regression),而是属于分类(Classification)问题。
假设函数(Hypothesis)的表达
首先假设函数要满足值在[0, 1]之间,满足这个值域的一个典型函数就是信号函数(sigmoid function,又称逻辑函数(logistic function)):
\[g(z) = \dfrac{1}{1 + e^{-z}}\]函数图像为:

这个函数的定义域(自变量z的取值范围)是$(-\infty, +\infty)$,由于训练集的x取值范围一般不能满足这个定义域,所以可以尝试进行一个线性变换,将假设函数满足信号函数的形式。也就是构造一个函数,使定义域满足训练集中x的取值,值域满足$(-\infty, +\infty)$:
\[z=θ^Tx\]这样定义出来的假设函数为:
\[h_\theta(x) = g(\theta^T x) = \dfrac{1}{1 + e^{-(\theta^T x)}}\]构造出模型之后可以反过来检验一下模型的合理性:定义域、值域都满足要求,并且变化规律也与训练集中的数据相符。
然后可以看出,根据这个模型预测的结果其实是代表着一个概率。同样以0.5为临界点,预测值大于0.5是认为值为1,否则为0。其实预测值代表的是一个概率,表达的意义是在这个$\theta$和给定的x情况下,预测值为1的概率是$h_\theta(x)$,预测值为0的概率是$1 - h_\theta(x)$。用数学意义表达是
\[\begin{align*}& h_\theta(x) = P(y=1 | x ; \theta) = 1 - P(y=0 | x ; \theta) \newline& P(y = 0 | x;\theta) + P(y = 1 | x ; \theta) = 1\end{align*}\]决策边界(Decision Boundary)
在只有一个feature的情况下,存在一个临界点,临界点两边的x对应的预测值总是不相等;在有两个feature的情况,$x_1$和$x_2$组成的平面上存在一条线,这条线两边的$(x_1, x_2)$对应的预测值总是不相同。这里提到的一维空间中的临界点、二维空间中的线(三维空间中是一个面)叫做决策边界。
当$x^{(i)}$取值刚好在决策边界上时,可以归为0或者1任意一类。
从决策边界的这个特性可以用公式表示:$g(z) = 0.5 \Rightarrow z = 0$
用之前肿瘤的例子就是$\theta_0 + \theta_1 * x = 0$,举一个二维空间的例子,有两个feature,$x_1$和$x_2$的分布如下图左边;
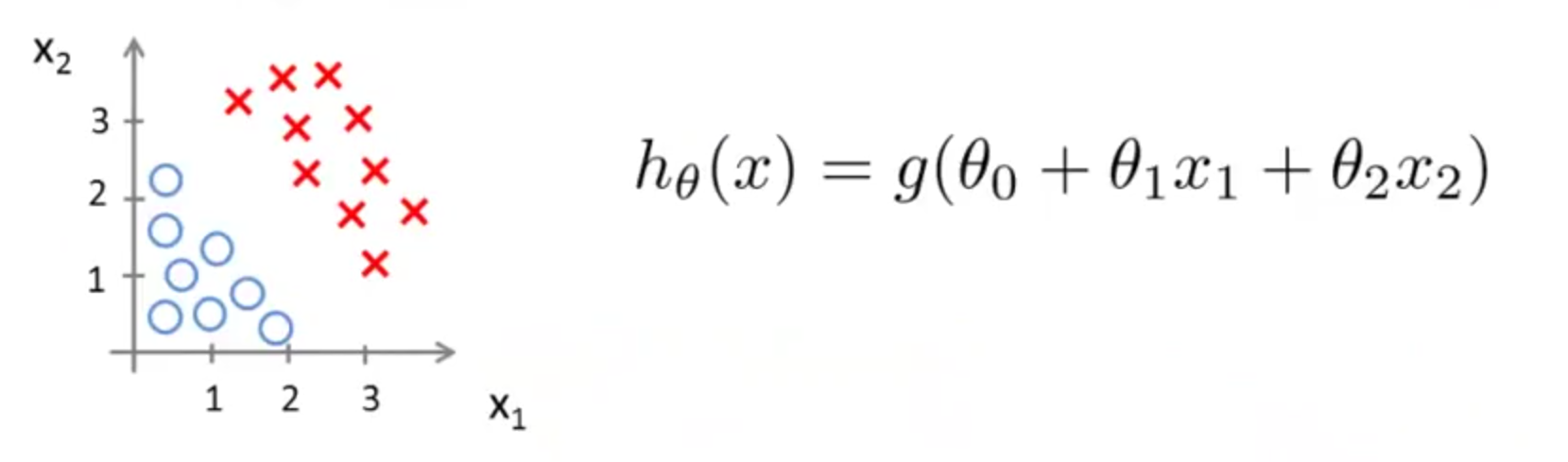
右侧为这个假设函数的模型,决策边界的数学表示就是$\theta_0 + \theta_1 x_1 + \theta_2 x_2 = 0$,也就是$\theta^T X = 0$,这条线在坐标轴上的位置大致会经过圆圈和红色叉之间的空隙。
二维空间的决策边界不一定是一条直线,也有可能是闭合的不规则图形:
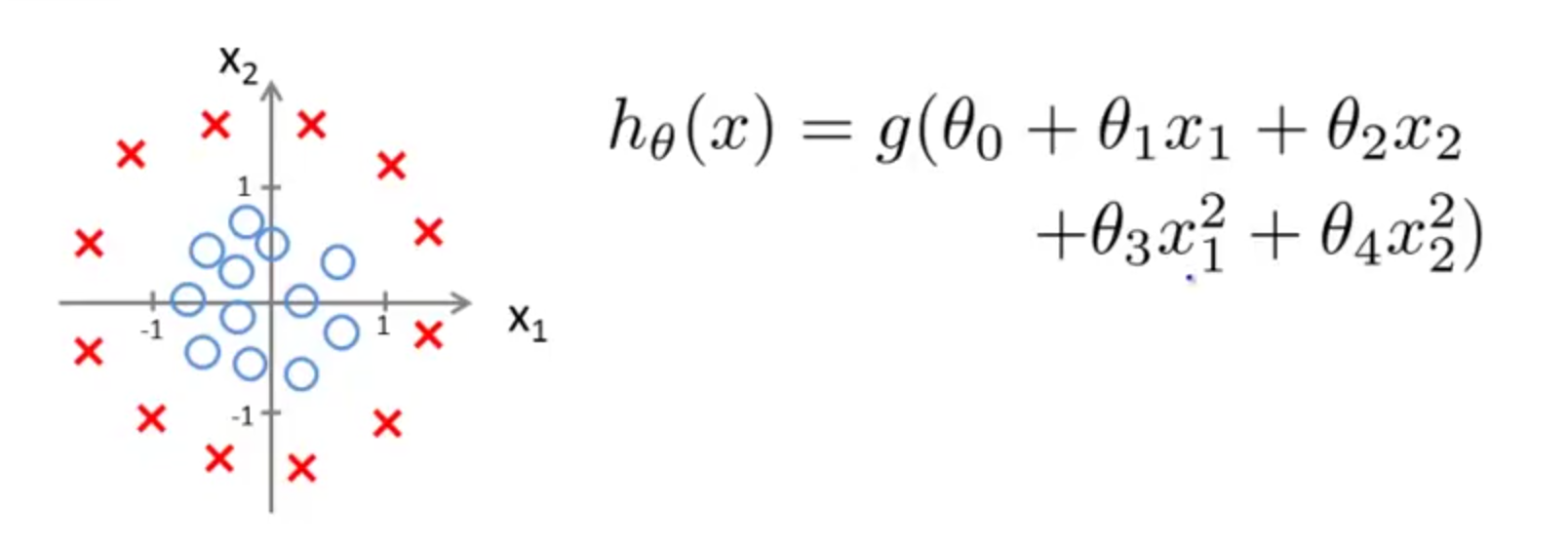
这个情况下的决策边界就是一个圆,数学表示为;$\theta_0 + \theta_1 x_1 + \theta_2 x_2 + \theta_3 x_3^2 + \theta_4 x_4^2 = 0$
平面中也有其他的圆锥曲线(conic section)或者不规则图形能作为决策边界。
无论二维或者是三维,决策边界允许不闭合的情况,比如二维中的直线、双曲线的一侧等都可以作为决策边界,但是不闭合的时候都可以空间无限延伸,在图形上的体现就是把预测值不相等的情况完全隔开。
一点题外话,其实我个人一直以来的想法是直线也是闭合的,比如说x轴,我会认为$-\infty $和$+ \infty$其实是一个点,相交的位置在复平面,这种情况下x轴是复平面上的一个圆在一维空间下的展开。或者另一种想法是x轴是复平面上的一个圆在一维空间的投影,这时$-\infty $和$+ \infty$在复平面的连线是这个圆的直径,并且这条直径与x轴平行。当然,这两个想法都是我瞎想的,没有深入研究过,也没有数学上的证明。
决策边界是假设函数$h_\theta(x)$自身的性质,与训练集无关。
不过假设函数的系数原本就是通过训练集不断尝试得到的,按照作者的说法应该是要这么理解:这个假设函数原本就是存在的,只是权衡训练集中的数据,恰好选用了这个预测函数,换一下迭代次数可能最终得到的$\theta$会不一样,这时就是另外一个假设函数了,这时的决策边界就是根据新的假设函数来的。进一步讲,有可能对同一个训练集选取的模型就可能是另外一种模型,决策边界当然就会有很多种不同的可能,如果决策边界由训练集决定,可以推断出一个训练集只对应一个决策边界,只有一个假设函数,这显然与常理不相符合。
成本函数(cost function)
成本函数反应了预测错误时的代价,回想之前的线性回归模型,成本函数$J(\theta)$随着$(h_\theta(x) - y)$的增大而增大,当预测足够准确时,$h_\theta(x) = y$,代价函数值为0,预测足够不准确时成本函数的值也会足够大。
结合这个特性来分析逻辑回归的成本函数,首先分开考虑,当实际值y=1的时候,如果预测值为1,成本函数应该是0,并且在$x \in [0, 1]$中,$h_\theta(x)$随着x的减小而增大,反过来也要有类似的性质。根据这些性质,结合最大似然法能得到逻辑回归成本函数的写法:
\[\begin{align*}& J(\theta) = \dfrac{1}{m} \sum_{i=1}^m \mathrm{Cost}(h_\theta(x^{(i)}),y^{(i)}) \newline & \mathrm{Cost}(h_\theta(x),y) = -\log(h_\theta(x)) \; & \text{if y = 1} \newline & \mathrm{Cost}(h_\theta(x),y) = -\log(1-h_\theta(x)) \; & \text{if y = 0} \end{align*}\]这个成本函数符合我们直观的感受,无论y的取值是0还是1,当预测值和实际值相符的时候成本函数值是0,预测值与实际值偏离的越大,成本函数的值越大,这能使迭代过程比较偏向正确的值。另外一点是,当完全预测失败时,成本函数的值会变得无穷大,之前有提到过,假设函数$h_\theta(x)$代表的是预测值为1的概率,如果假设函数的值是1,说明这个模型预测给定的情形下,值肯定是1,但是如果实际值为0,说明这个模型做了一个非常不靠谱的预测,为了防止迭代过程中得到这样的模型,学习算法会给这样的情况一个无穷大的成本函数值。
上面这个成本函数可以写成一个式子,避免分段函数的情况
\[J(\theta) = - \frac{1}{m} \displaystyle \sum_{i=1}^m [y^{(i)}\log (h_\theta (x^{(i)})) + (1 - y^{(i)})\log (1 - h_\theta(x^{(i)}))]\]写成矩阵的形式就是:
\[\begin{align*} & h = g(X\theta)\newline & J(\theta) = \frac{1}{m} \cdot \left(-y^{T}\log(h)-(1-y)^{T}\log(1-h)\right) \end{align*}\]梯度下降算法(Gradient Descent)
将逻辑回归的成本函数带入梯度下降算法中,可以得到
\[\begin{align*} & Repeat \; \lbrace \newline & \; \theta_j := \theta_j - \frac{\alpha}{m} \sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)}) x_j^{(i)} \newline & \rbrace \end{align*}\]虽然这个看起来和线性回归的形式一模一样,但是由于两个模型的假设函数$h_\theta(x)$不相同,所以这两个模型的梯度下降算法迭代的步骤是不一样的。
写成矩阵的形式是:
\[\theta := \theta - \frac{\alpha}{m} X^{T} (g(X \theta ) - \vec{y})\]高级优化
除了梯度下降算法外,还有很多算法能通过成本函数$J(\theta)$以及成本函数关于每个维度$\theta$的偏导数求出使成本函数最小的$\theta$值。
其中有些算法中间的实现比较复杂,但是可以直接使用Octave已经封装好的实现而不需要理解算法的原理。
可以通过这样使用函数fminunc来达到获取$\theta$的效果:
options = optimset('GradObj', 'on', 'MaxIter', 100);
initialTheta = zeros(2,1);
[optTheta, functionVal, exitFlag] = fminunc(@costFunction, initialTheta, options);
前面的optimset是设置函数执行的选项,MaxIter, 100代表最大迭代次数为100次。GradObj设置为On,这个告诉fminunc我们的函数costFunction返回成本函数和每个$\theta$的偏导数,然后fminunc函数能在最小化成本函数的过程中使用梯度。
fminunc函数的第一个参数代表了一个函数指针,costFunction是一个函数,这个函数返回成本函数$J(\theta)$以及成本函数关于每个维度$\theta$的偏导数。第二个参数是$\theta$的初始值,这个参数至少要有两个维度,不能是实数。第三个参数是前面设定的选项。
这样的做法比梯度下降的优势在于收敛速度更快(基于算法内部的实现)并且不需要选择下降速率$\alpha$,缺点是原理复杂。
多类分类问题
之前讨论的都是根据feature分成两类的问题,但是实际的机器学习要解决的问题中有些需要处理多类分类问题。比如说根据邮件内容区分邮件是关于工作、朋友、家庭或者是兴趣的;将天气区分为晴、多云、雨等。
对于多类分类的问题,可以划分为很多y={0, 1}的情况。对于每一个训练集中的类别,我们制造一个伪训练集,将这个类别作为正类(y=1),其余作为负类(y=0),这样就变成了之前的y={0, 1}的分类问题。这样能算出这个分类情况下的假设函数$h_\theta(x)$,用这个假设函数预测的结果是某条数据归类于这个类别的概率。将所有的类别都经过这样的处理能得到很多的假设方程,对于需要判断的数据X,可以带入所有的假设函数中,取假设函数值最大的那个为最终的类别。表示这个数据归为这个类别的概率最大。
总的来说就是先为每个类别i训练逻辑回归分类器$h_\theta(x)^(i)$,用这个分类器预测y=i的概率,然后将这个分类器作用在新的数据x上,选取值最大的$h_\theta(x)$对应的类别作为这个数据的类别
过度拟合的问题
如果采用的模型有过度拟合问题,这个模型在训练集中的预测值会表现的非常好,但是对于新的数据表现往往偏差较大。
以之前学习的使用线性回归模型预测房价的例子,左边的图是欠拟合的例子,使用一次方的线性模型,没有完全表示出训练集的特征,预测数据会有较大的偏差;中间的模型添加了一个平方项,能比较合适的表达模型的特征并且作出其他数据的预测;右边的结果是因为加入了面积的四次方,虽然在训练数据中拟合的很好,但是对于新的数据预测结果往往会很差,因为这个模型从图形上看来都不太符合常理,仅仅是为了适应训练集中的数据造成这样的图形。
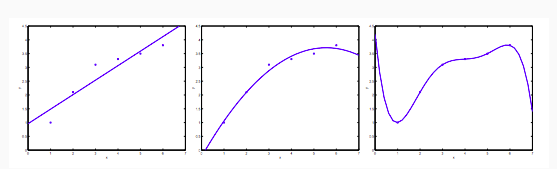
过度拟合的问题可能同时出现在线性回归和逻辑回归中(逻辑回归中直观的体现为决策边界为了适应训练集中的数据呈现十分扭曲的结果,如下图)
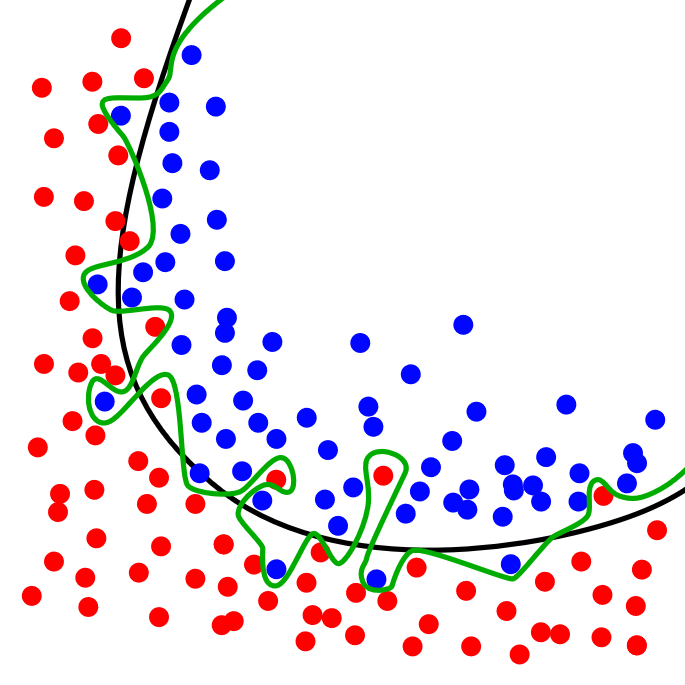
避免过度拟合的方法主要有两种:
- 减少特征数目:人为判断需要保留的feature,或者使用之后学习到的模型选择算法
- 正规化:保留所有feature,但是减少参数$\theta_i$的幅度。当有很多有用的feature时,正则化效果很好。
带有正规化的成本函数
针对过度拟合的问题,可以通过修改成本函数的方式来避免,一个做法是惩罚系数项,将成本函数修改为:
\[J(\theta) = min_\theta\ \dfrac{1}{2m}\ \left[ \sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})^2 + \lambda\ \sum_{j=1}^n \theta_j^2 \right]\]在原先的成本函数中添加了针对系数$\theta$的惩罚,在后面部分惩罚的内容中没有包含$\theta_0$,λ表示正规化参数,用来权衡是否过度拟合的比重。当λ过小的时候会出现于之前过度拟合的问题,如果λ过大,会弱化前半部分,导致欠拟合。
正规化线性回归
由于正规化改变了成本函数的定义,现在需要更新线性回归的梯度下降法和Normal Equation方法
梯度下降法
将更新后的成本方程带入梯度下降的定义中,得到
\[\begin{align*} & \text{Repeat}\ \lbrace \newline & \ \ \ \ \theta_0 := \theta_0 - \alpha\ \frac{1}{m}\ \sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})x_0^{(i)} \newline & \ \ \ \ \theta_j := \theta_j - \alpha\ \left[ \left( \frac{1}{m}\ \sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})x_j^{(i)} \right) + \frac{\lambda}{m}\theta_j \right] &\ \ \ \ \ \ \ \ \ \ j \in \lbrace 1,2...n\rbrace\newline & \rbrace \end{align*}\]这个式子中将j=0的情况单独列出来是因为正规化过程中没有对$\theta_0$做出惩罚,对于j不等于0的情况,可以将公式改写成下面这个形式:
\[\theta_j := \theta_j(1 - \alpha\frac{\lambda}{m}) - \alpha\frac{1}{m}\sum_{i=1}^m(h_\theta(x^{(i)}) - y^{(i)})x_j^{(i)}\]这样写的能直观的表现出正规化的过程到底做了什么,上面这个式子的后半部分和之前的梯度下降法相同,前半部分多了一个$(1 - \alpha\frac{\lambda}{m})$,在正常情况下,这个算式的值会一直小于1,但是不会小很多(原因是α、λ、m都大于0,并且梯度下降法的下降速率α会比较小,训练集的个数m会比较大),这相当于在之前没有正规化的基础上,每次迭代时对$\theta$进行一次收缩,使这个值更加接近0。
Normal Equation
根据之前Normal Equation方法的思想,将成本函数$J(\theta)$对每个方向的θ求偏导数,将结果置为0,解出每个θ的值,最终结果为(推导过程省略):
\[\begin{align*}& \theta = \left( X^TX + \lambda \cdot L \right)^{-1} X^Ty \newline& \text{where}\ \ L = \begin{bmatrix} 0 & & & & \newline & 1 & & & \newline & & 1 & & \newline & & & \ddots & \newline & & & & 1 \newline\end{bmatrix}\end{align*}\]L是一个(n + 1) * (n + 1)的矩阵,除了左上角为0外、其余对角线的位置都是1,非对角线的地方值都是0
利用了正规化的方法之后,还能解决之前的一个问题,在前面使用Normal Equation的时候可能会出现一个问题就是$X^T X$可能是奇异矩阵,无法得到逆矩阵。经过正规化处理后,能从数学上证明这个矩阵(X^TX + \lambda \cdot L \right)一定有逆矩阵。
正规化逻辑回归
与上面的做法类似,我们这里直接写出正规化后逻辑回归的成本方程:
\[J(\theta) = - \frac{1}{m} \sum_{i=1}^m \large[ y^{(i)}\ \log (h_\theta (x^{(i)})) + (1 - y^{(i)})\ \log (1 - h_\theta(x^{(i)}))\large] + \frac{\lambda}{2m}\sum_{j=1}^n \theta_j^2\]同样要注意后面针对系数$\theta$的惩罚同样排除了$\theta_0$。
类似的,梯度下降法可以改写成下面这种分段函数的形式。
\[\begin{align*} & \text{Repeat}\ \lbrace \newline & \ \ \ \ \theta_0 := \theta_0 - \alpha\ \frac{1}{m}\ \sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})x_0^{(i)} \newline & \ \ \ \ \theta_j := \theta_j - \alpha\ \left[ \left( \frac{1}{m}\ \sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})x_j^{(i)} \right) + \frac{\lambda}{m}\theta_j \right] &\ \ \ \ \ \ \ \ \ \ j \in \lbrace 1,2...n\rbrace\newline & \rbrace \end{align*}\]与正规化处理之前相同,这里的式子看起来与线性回归的相同,但是由于假设函数不一样,这个方法与线性回归的梯度下降法是两个不相同的方法。
参考
所有笔记链接
- [笔记]0.machine-learning-第0篇笔记
- [笔记]1.machine-learning-介绍
- [笔记]2.machine-learning-多元线性回归
- [笔记]3.machine-learning-分类
- [笔记]4.machine-learning-神经网络
- [笔记]5.machine-learning-成本函数和反向传播算法
- [笔记]6.machine-learning-应用机器学习的建议
- [笔记]7.machine-learning-支持向量机
- [笔记]8.machine-learning-分类
- [笔记]9.machine-learning-异常检测
- [笔记]10.machine-learning-大数据量下的梯度下降算法
- [笔记]11.machine-learning-应用示例:照片中的光学字符识别