

这个是我在学习Stanford University机器学习课程中做的一些笔记,有些是靠自己的理解写的,也许不一定准确。课程地址:https://www.coursera.org/learn/machine-learning/home
- 定义
- 监督学习(Supervised Learning)
- 非监督学习(Unsupervised Learning)
- 模型和成本函数(cost function)
- 梯度下降算法
- 线性代数相关知识
- 参考
- 所有笔记链接
定义
Tom Mitchell (1998) Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
现在的很多软件已经复杂到没有办法通过传统的代码方案来处理复杂的情况了,比如自动驾驶的汽车和围棋等。道路的情形千变万化,很难定义出某一个特定的情况汽车应该做出什么行为,一个靠谱的办法是教给汽车一些特定的情形,比如前面有人通过应该减速或者停车让行,下次汽车遇到类似的情形也会做出类似的判断,实际上我们学开车的时候驾校也没有教给我们所有的情况,结合具体情形做出正确的判断才是我们大多数人的做法。
如果按照传统的写法,比如现在我们要考虑前方多少米有人,前后左右其他的汽车,还要结合交通指示灯来中和判断,就算这样的软件能研发出第一个版本,后面增加了一种情况(比如交警指挥时),我们需要在所有指令执行之前再加上一个交警指挥的判断,代码的改动量非常大,并且软件的稳定性肯定不太好。如果使用机器学习的方式,只需要在训练集中多加入一个feature,重新训练一次原有的数据就行了(如果这个技术发展成熟之后也许不需要重新开始一个新的训练,也许我们能储存之前训练的结果进行增量的训练,毕竟我们学习新的规则时不需要重新考一次驾照,我是相信之后机器学习能做到这个程度的),无论是从软件软件的稳定性还是实际操作的可行性,机器学习都是自动驾驶不可或缺的一个技术。
监督学习(Supervised Learning)
从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是包括输入和输出,也可以说是特征(feature)和目标(target)。
- 回归(Regression):预测连续值的输出
- 分类(Classification):预测离散值的输出
监督学习就是有些用来做训练的数据,这些数据的答案都是已知的,比如手写辩识,有50000张写了数字(0 ~ 9)的小卡片,将这些卡片拍照输入到计算机中,告诉计算机每张图片代表的是数字几,让计算机自己去学会辨认卡片上的数字。然后有类似的卡片计算机会识别出卡片上的数字,这个过程就是监督学习。
而回归和分类的区别在于输出的值是否连续,比如提供很多的房子面积,地理位置,结构等咨询(特征),告诉这些房子的售价(目标),需要知道其他房子的售价,这个过程由于房价是连续性的,所以一般采用回归分析。(当然强行说是分类也不是不可以,比如分成不同的价格区间,但是总是感觉有点牵强,毕竟分的类别太多了的话好像用分类是没办法处理的)。而分类的例子是给一些病人的症状年龄和病史等信息,判断病人是不是流行性感冒,这个问题的结果集只有两个,是或者否(离散值的输出),只需要根据不同feature把结果归到这两类里面就行了,所以这个一般是分类问题。
非监督学习(Unsupervised Learning)
与监督学习相比,训练集没有人为标注的结果。常见的无监督学习算法有聚类(Cluster analysis)。 非监督学习的例子一般是结果集太多并且不是连续性的,比如从网上爬到了今天的所有新闻,要把这些新闻分成不同的类别,在分类完成之前没有人清楚应该分成哪些类别,也不一定有历史分类数据作为参考,所以一般是提取特征将每则新闻分布在一个特征空间里面,然后对这些空间上的点(一般是一个点代表一则新闻)做分群,相似的新闻自然而然会被分在同一群里面,最终的结果就是将新闻分成了不同的类别。
模型和成本函数(cost function)
监督学习的一般步骤是给定feature和target,让机器学习中间的转换步骤,学习完这个步骤之后,需要在后面有输入类似feature的数据时,输出的target足够合理。以房价举例就是:现在有一些训练数据(train set),100平米的房子卖100万,150平米的150万,200平米的200万,机器获取这些训练数据和结果之后学习到了一个假设,有了这个假设(hypothesis)之后,我们询问机器,130平米的房子价格应该是多少,从直觉上来讲,机器给出的答案应该在130万左右,这时我们认为机器给出的预测足够合理。
但是实际上机器并没有这么智能,或者说机器缺乏我们看到上面这些训练数字时所拥有的直觉(毕竟很少会有人拿机器学习预测这么直观的模型),对于机器来说,得出这个结论需要一些重要的东西:
第一个就是一个模型(model):人类可以根据这些train set的分布判断这是一个线性模型,或者从直觉上猜到这是一个线性模型(Linear model),但是机器缺乏这种直觉,他需要人类提供一个模型,然后他的强项在于计算这个模型的参数,使得通过这个模型猜出的结果最好。实际上,是人类告诉机器,这个训练集可以用线性模型尝试一下,然后人类有一个已知答案的集合(test set)用来检测这个模型到底用线性模型是否合适,如果最后结果发现测试的还比较满意一般就表明模型没有太大问题了。
给定了模型之后机器要确定模型的参数,使最后的预测的结果最好。线性模型只是定义了$h_\theta(x) = \theta_0 + \theta_1x$这种形式,并没有确定$\theta_0$和$\theta_1$的值,机器现在需要根据训练集中的数据和模型来得到合适的$\theta_0$和$\theta_1$,但是机器并不知道什么样的值是合适的,这时候需要人类提供另外一个函数——成本函数(cost function),然后给机器下一个目标,确定$\theta_0$和$\theta_1$的值,使成本函数的结果最小。在回归分析中有一个常见的cost function: \(J(\theta_0, \theta_1) = \cfrac{1}{2m} \sum_{i=1}^m( h_\theta(x_i) - y_i )^2\)
其中m是训练集合的大小(其中资料条数),这个cost function是一个与$\theta_0$和$\theta_1$相关的函数(这个函数的得来可以参考相关的paper,其实实际中不只是有这一种成本函数,这里只是恰好选择了这个)。有了假设函数($h_\theta(x)$)和成本函数($J(\theta_0, \theta_1)$),通过不停的将训练集在这两个函数中尝试,可以获得使成本函数最小的$\theta_0$和$\theta_1$。
这里首先做一个简化:将$\theta_0$假设为0,这时候就只有一个变量,很容易将成本函数化简为仅与$\theta_1$相关的二次函数,通过坐标系很容易看出使成本最小的$\theta_1$的值。
有了以上的知识再来考虑$\theta_0$存在的情况就稍微简单一点。这时候需要一个空间坐标系,水平方向是$\theta_0$和$\theta_1$的不同取值,z轴方向是成本函数的取值,在空间中的图形大概长这样:
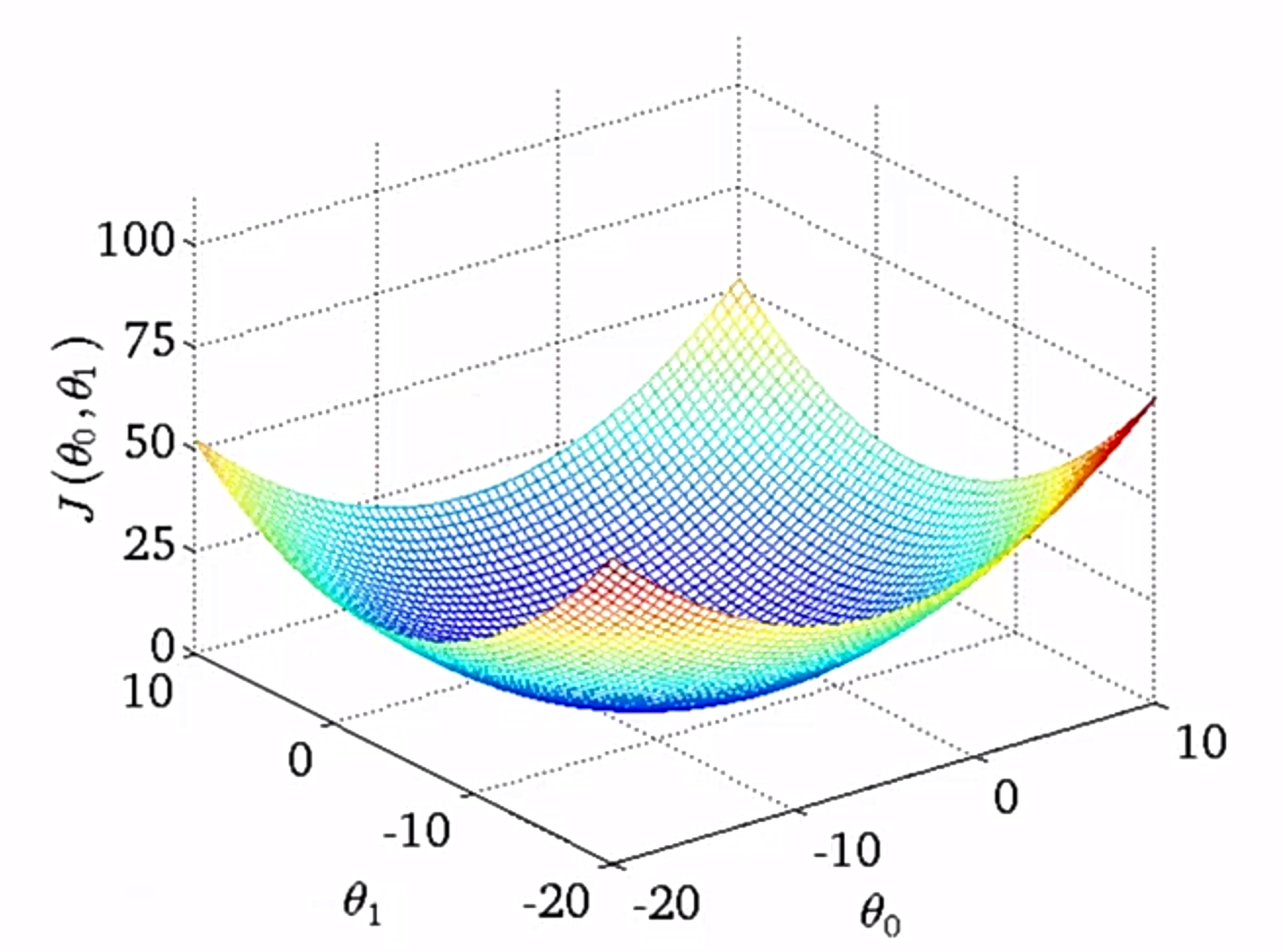
但是在平面的表示一般是用轮廓图表示,有点像地理学里面的等高线:
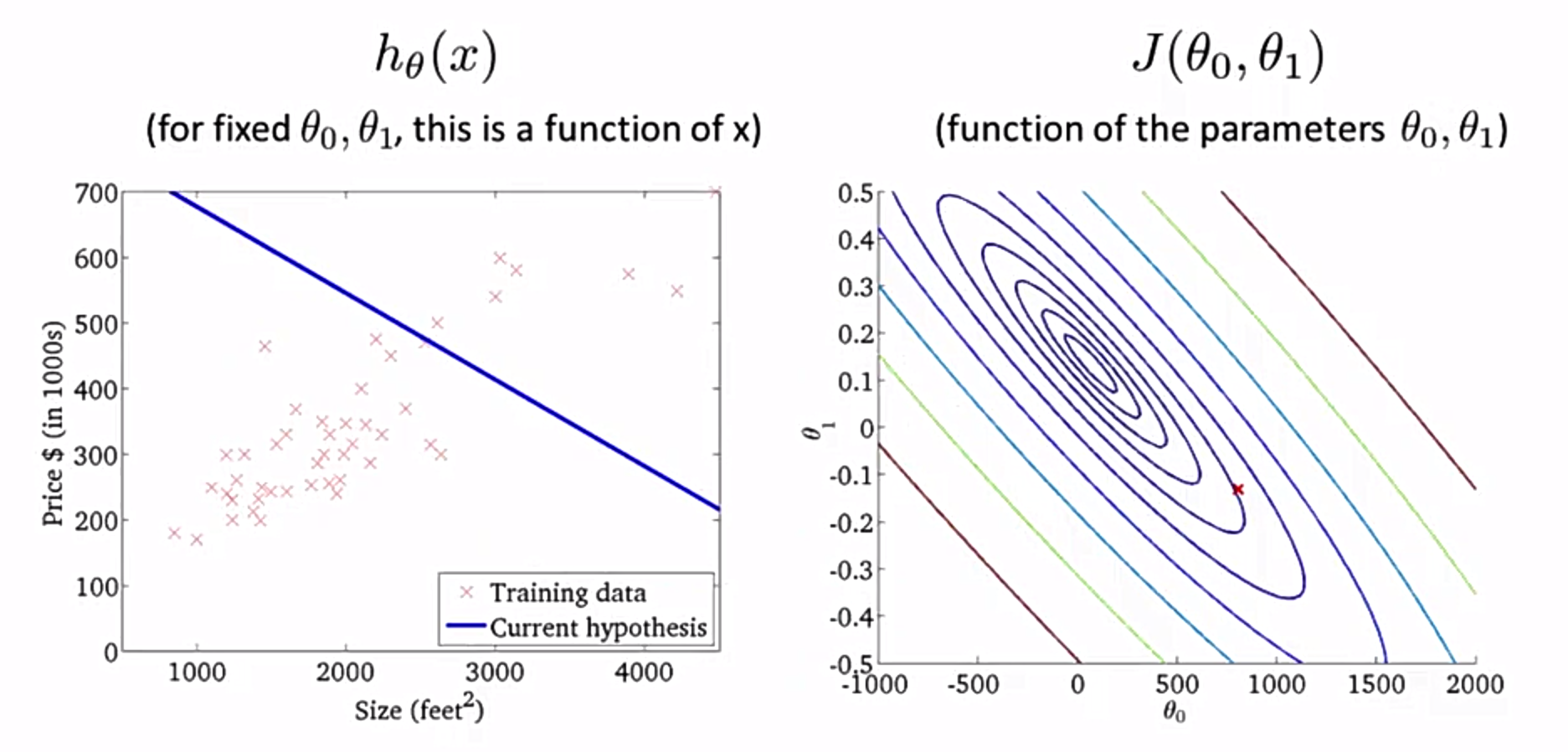
右边的是轮廓图,这个图中演示了一种$\theta_0$和$\theta_1$取值情况下的$h_\theta(x)$图形和$J(\theta_0, \theta_1)$的值(右边那个图中有个小红点就是,小红点的横纵坐标代表$\theta_0$和$\theta_1$的值,对应的颜色代表$J(\theta_0, \theta_1)$的值),可以看出这种情形下效果并不好,所以计算机会不停的寻找那个最优点,直到cost最小,这个示例中是右边图中那一群椭圆的正中间。
扩展到更复杂一点的情况已经不能用图形表示了,只能将低维度情况下考虑清楚,高纬度采用数学方法来证明。
线性模型就像是机器学习中的”Hello World”,感觉真正使用过程中很少会用机器学习来处理这种只有一个feature的线性模型,毕竟已经有通用公式来处理这个线性模型了,一般一点的编程计算器都能把这个问题处理的很好,并且结果可能比机器学习的方法还要精确一些,这个公开课采用线性模型的原因大概是线性模型太容易理解了,很容易使用这个模型让大家熟悉机器学习分析问题的步骤(后面的深度学习(Deep Learning,是机器学习的一种特殊情况)大部分人也是从线性模型开始的)。
总的来说,线性问题的机器学习解法是先建立model,并确立cost function,不停的采用train set来训练model中的参数,使得cost function最小。最后往往会采用test set进行结果的检验,看是否与实际情况相符合。
梯度下降算法
之前介绍了机器学习的一般步骤,最终是要找出模型的各种参数使成本函数最小,但是没有说明该怎么寻找这个参数。显然不会是计算空间中的所有点,一个一个比对成本函数的值,目前的计算机还做不到这个水平。一般来说,采用的方法是梯度下降算法。
现在假设有两个参数的情况,成本函数在空间中的分布是类似于下图的形状,可以想象成是地形图:
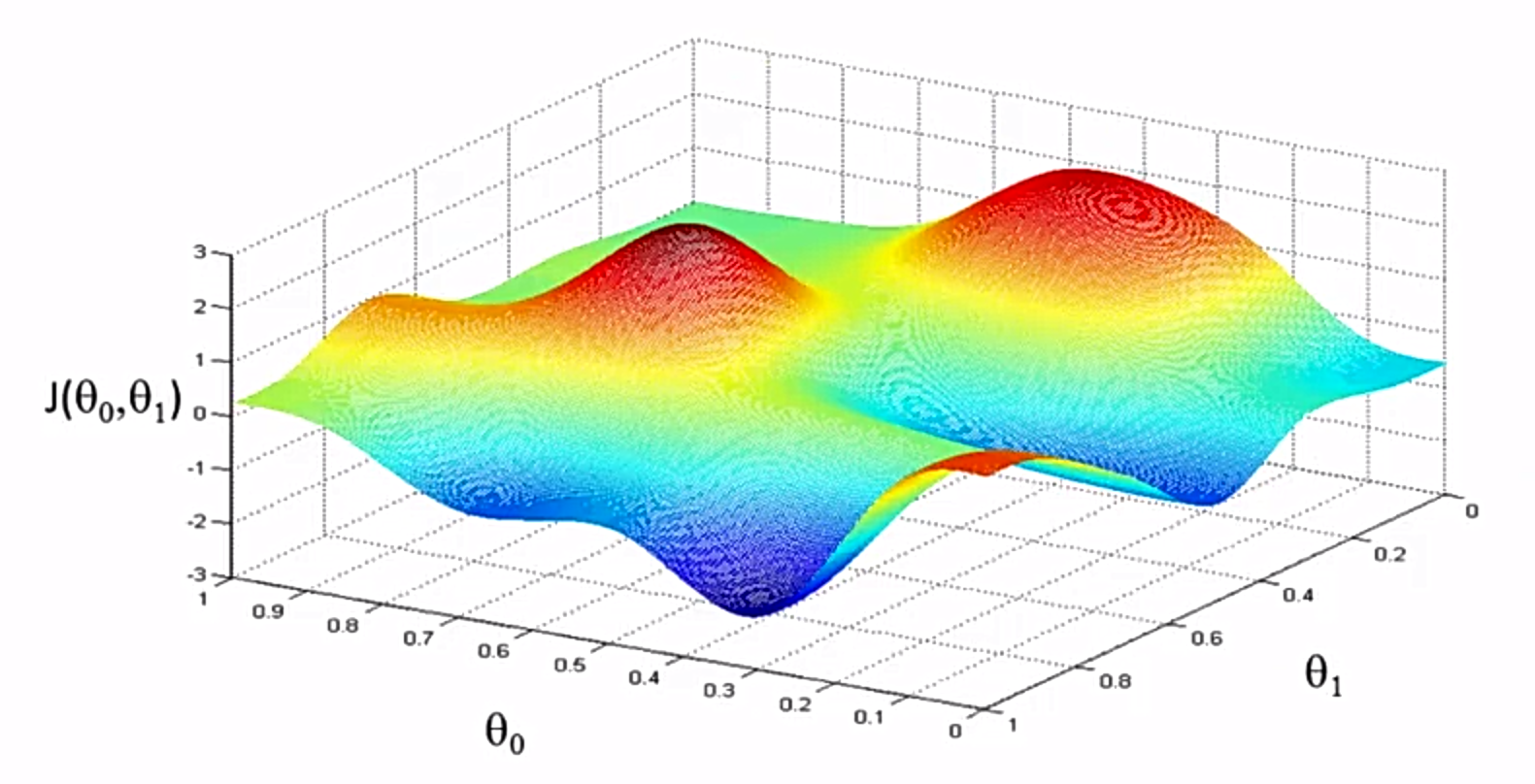
现在要求的就是平面中的某一个点,让对应的成本函数高度最低,直观上来讲就是要获取海拔最低的点的经纬度。
虽然求整个空间中的海拔最低点有点困难,但是可以通过梯度下降算法获取局部的一个最低的点,假设一个人站在某个山顶上,要到达附近的海拔最低的地方,步骤大概是先四周看看,找到下降的最快的方向,往前走一步,然后重复这个步骤,等到了最低点之后会发现下降的最快的方向已经不存在了(因为是在最低点),这时候就可以确认,所在的位置是这附近的一个海拔最低的地方(局部最优解)。但是有个问题是在他开始下降的附近有一个山脊,他如果从山脊的另外一边开始下降找海拔最低的点,可能就找到了另外一个地方
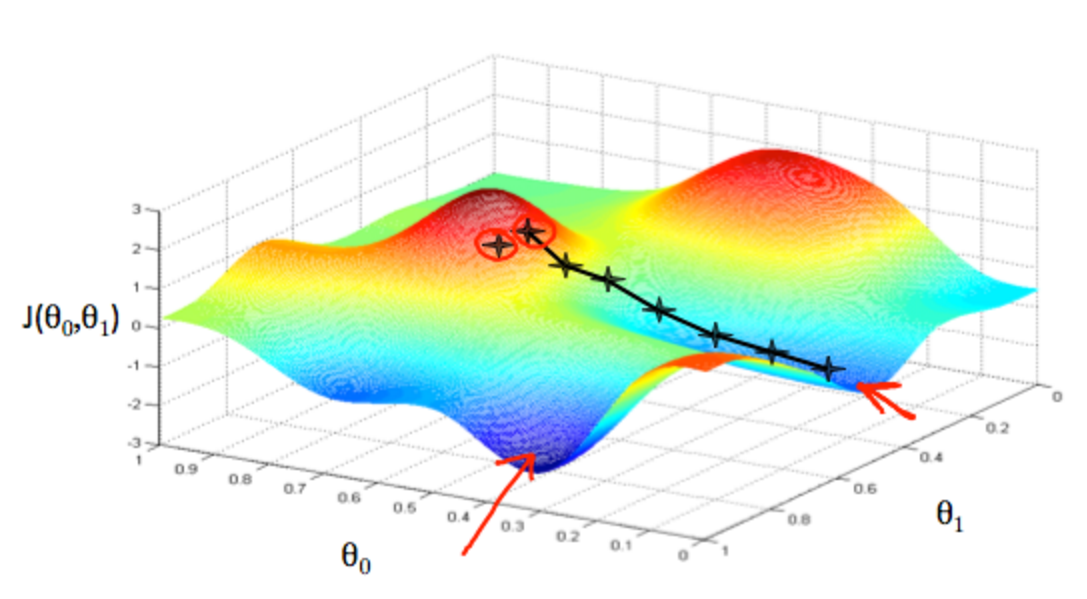
例如上图红色圆圈框起来的两个点是很近的两个初始位置,这个算法导致下坡之后找的海拔最低点相差会很远,并且不能保证所处的点是整个空间中海拔最低的点。
这个过程翻译成算法就是:
重复以下步骤直到收敛\(θ_j:=θ_j−α\cfrac{∂}{∂θ_j}J(θ_0,θ_1)\)
其中 j=0,1 表示特徵索引序号.
这门课中 := 符号表示赋值, = 表示相等,与一般编程里面不一样
这个公式是不停的拿右边的来结果来赋给左边的变量,一次次的迭代直到找到局部最优解,每个迭代的过程就类似于之前例子中朝着下降最快的方向迈了一步。α表示速率,类似于下山时候迈开的步子有多大,这个值是人为给定的,值太大太小都有问题。
后面的$\cfrac{∂}{∂θ_j}J(θ_0,θ_1)$是成本函数关于$θ_j$的偏微分,可以暂时理解为这个值越大,往前迈一步下降的速度就越快(这个不太对,但是这个情况下可以类似这么理解),在最优解的地方,已经找不到能下降的方向了,这时候偏微分的值为0,会导致$θ_j$的值不变,无论重复多少次这个步骤,所处的位置都会固定不动,这个时候我们称之为收敛。
这里需要注意一个细节,就是迭代过程中$θ_0$和$θ_1$是同时改变的,同时改变的意思是在每次计算$θ_j$的时候用的都是上一次迭代后$θ_0$和$θ_1$的值。
e.g.

这个情况计算下一步的$θ_0$和$θ_1$应该都根据这一步之前的值。$θ_0$ := $θ_0$ + $\sqrt{θ_0θ_1}$这里右边的 $θ_0 + \sqrt{θ_0θ_1}$应该根据1和2给值,算出来$θ_0 = 1 + \sqrt2$,值得注意的是,这时候算$θ_1 := θ_1 + \sqrt{θ_0θ_1}$时,$θ_0$ 的取值仍然是1而不是刚刚算出来的$1 + \sqrt2$,所以$θ_1 = 2 + \sqrt2$
现在考虑速率α的取值,将问题简化到二维的情况(假设$θ_0 = 0$),只考虑一个参数来分析α过大和过小会出现什么问题。
首先α过大代表我们下山的步伐迈的比较大,一个可能的情况是直接越过了这个局部最优解,跨到了另外一个最优解中,不过这个问题倒是不太严重,比较严重的问题是α过大可能导致最后无法收敛。假设有个成本函数为$J(θ_1) = θ_1 ^ 2$,右边的值为$θ_1 - α\cfrac{d}{dθ_1}J(θ_1) = (1 - 2α)θ_1$,如果这时候α > 1,比如说取α = 2,每次会将 $-3θ_1$的值赋给$θ_1$,只要初始条件下$θ_1$的值不为0,就会导致计算无止境的进行下去。而α过小的结果是计算的次数太多,造成电脑负担加重。
其他一些梯度下降算法的缺点可以参考梯度下降法-维基百科
将上面提到的成本方程和梯度下降算法结合起来就能解决这个线性拟合的问题了(线性问题的成本函数不存在局部最优解,只有一个全局最优解,空间分布的情况上面有图提到过,像一个碗的样子),将成本函数带入算法中,不停的迭代$θ_0$和$θ_1$的值,直到值收敛。这里每次计算都将所有的训练数据带入了成本函数中,叫做批量梯度下降(batch gradient descent)。
线性代数相关知识
这门课程需要一些线性代数相关的知识,不够还好都挺基础的,然而不想写在这里(打公式好累),复习的时候可以参照这个链接:ML:Linear Algebra Review
然后有几点相关知识的运用是链接里没有提到的,假设有四个房子(面积(单位:$feet ^ 2$)分别为:2104、1416、1534、852)以及一个线性的假设函数$h_θ(x) = -40 + 0.25x$,现在要预测四个房子分别的售价,传统程序的写法是循环四次,每次套用公式计算一个房子的价格,然利用矩阵可以用下面的式子计算出来:
\[\begin{bmatrix} 1 & 2104 \newline 1 & 1416 \newline 1 & 1534 \newline 1 & 852 \end{bmatrix} * \begin{bmatrix} -40 \newline 0.25 \newline \end{bmatrix}\]最后的结果是一个4 * 1 的向量,向量的第i行代表第i个房子的价格.
进一步,如果有多个不同的假设函数,比如说三个:
\[\begin{cases} h_θ(x) = -40 + 0.25x \newline h_θ(x) = 200 + 0.1x \newline h_θ(x) = -150 + 0.4x \end{cases}\]如果要用三个假设函数来分别预测之前房屋的价格,可以直接用一个矩阵相乘解决:
\[\begin{bmatrix} 1 & 2104 \newline 1 & 1416 \newline 1 & 1534 \newline 1 & 852 \end{bmatrix} * \begin{bmatrix} -40 & 200 & -150 \newline 0.25 & 0.1 & 0.4 \newline \end{bmatrix} = \begin{bmatrix} 486 & 410 & 692 \newline 314 & 342 & 416 \newline 344 & 353 & 464 \newline 173 & 285 & 191 \end{bmatrix}\]最后结果中的每一列表示不同的假设函数算出的结果,每一行表示对应房间的预测价格
这种方式比起传统方法的好处首先是看起来简洁,大部分的编程语言都支持矩阵计算,能一行代码解决这个问题,其次是使用成熟的语言库可以减少自己的失误,并且内部的实现往往比写循环一个个计算要好一些,能提高计算效率。
参考
所有笔记链接
- [笔记]0.machine-learning-第0篇笔记
- [笔记]1.machine-learning-介绍
- [笔记]2.machine-learning-多元线性回归
- [笔记]3.machine-learning-分类
- [笔记]4.machine-learning-神经网络
- [笔记]5.machine-learning-成本函数和反向传播算法
- [笔记]6.machine-learning-应用机器学习的建议
- [笔记]7.machine-learning-支持向量机
- [笔记]8.machine-learning-分类
- [笔记]9.machine-learning-异常检测
- [笔记]10.machine-learning-大数据量下的梯度下降算法
- [笔记]11.machine-learning-应用示例:照片中的光学字符识别