

背景
这篇paper是基于上一篇Playing Atari with Deep Reinforcement Learning的改进,算法层面将前一篇提出的DQN(Deep Q Netword)加入了Target Q,并分析了通过这种网络具体学到的内容大致是什么。实验部分将之前的7个Atari游戏扩展到了49个Atari游戏中,实验结果比之前的paper效果更好,并且分析了不同游戏类型中的优势与局限性。
paper原文链接: https://www.nature.com/nature/journal/v518/n7540/pdf/nature14236.pdf
笔记链接:https://junmo1215.github.io/paper/2017/11/04/Note-Human-level-control-through-deep-reinforcement-learning.html
DeepMind在这篇paper中提到了,他们希望能做出通用人工智能,这就需要实作的AI不能仅仅局限于单一的问题。跟前面的paper中一样,他们不希望采用手动提取feature的方式,而是直接将游戏画面作为神经网络的输入,让网络自己练习从而面对一个游戏换面能做出正确的选择。这篇paper仍然是选择同样的算法同样的模型(network architecture)以及同样的超参数(hyperparameter)来解不同的游戏,并且与其他的方法比较。并且针对上一篇paper中Q值不稳定的问题分析了原因,从而引出一个改良的方式就是Target Q.
强化学习回顾
首先回顾一下为什么要使用强化学习,针对Atari游戏,如果使用监督学习,我们需要大量的训练样本(标注当前游戏状态和这个状态下agent应该怎么选择动作),往往我们很难拿到这么庞大的训练集,更加关键的是我们人类并不是这么学习的。
因此可以尝试使用强化学习来训练我们的agent,然而问题是不是每一帧画面都有标注好的reward能让我们的模型进行迭代学习,很多时候我们的操作很关键但是这个状态以及对应的动作并没有造成reward。所以需要想办法解决游戏过程中reward很稀疏并且常常有延迟的问题。
通过上篇paper中的基本假设可以推导出神经网络模型的迭代公式,并且实验已经证明了这种做法的效果很好并且具有通用性。
算法改良
迭代公式
使用非线性的方式(比如神经网络模型)模拟Q值的方式已经发现存在使Q值震荡甚至偏移的问题,可能的原因有以下几种:
- 训练的样本中状态之间有很强的关联。Q值的迭代变化可能会导致选择的策略不同,进使游戏过程中的状态分布有很大的变化,导致Q值不稳定。这个问题采用上篇paper中的replay memory机制在一定程度上可以避免。
- 当前的状态的预测值(Q)和理想值(target Q: $r + \gamma \max_{a’}Q(s’, a’)$ )之间的关联性也过强。针对这一点,DeepMind采用了一种冻结神经网络权重来获取target Q的方式。
与之前一样,游戏过程中不断把中间状态存储memory里面,在学习过程中随机抽取minibatch大小的样本进行loss的最小化,其中不同的地方在于更新过程中 $\max_{a’}Q(s’, a’)$ 的计算,之前是将 $s’$ 喂给要计算的神经网络,让这个网络输出Q值作为Target Q进行自身的迭代。现在的做法是新建了一个一样的网络,这个网络的参数会定期更新成正在训练的那个网络的参数,其他时候参数并不参与迭代。计算 $\max_{a’}Q(s’, a’)$ 的时候是用新的这个网络。
用公式表述就是:
\[L_i(\theta_i) = \mathbb{E}_{(s,a,r,s') \sim U(D)} [(r + \gamma \max_{a'}Q(s', a'; \theta^-_i) - Q(s, a; \theta_i))^2]\]与原来的公式对比就很容易理解其中的差别了:
\[L_i(\theta_i) = \mathbb{E}_{(s,a,r,s') \sim U(D)} [(r + \gamma \max_{a'}Q(s', a'; \theta_i) - Q(s, a; \theta_i))^2]\]改良后的公式中 $\theta^-_i$ 表示用来计算第i次迭代中target的网络参数。 $\theta_i$ 是我们在不停迭代的网络的参数,只有在固定的步骤之后我们才将 $\theta_i$ 替换到 $\theta^-_i$ 中。
算法改良
更新后的算法如下:

这部分只是在开始初始化了一个相同的神经网络 $\hat{Q}$ 然后在迭代过程中每C步将$Q$的权重复制给 $\hat{Q}$ 网络。
网络架构
网络的架构上仍然保持与之前一致,只是这次在一些参数的选择上讲的更加清楚。
- 使用frame-shipping技术的时候,上一篇paper在Space Invaders游戏选择每3帧观察一次并进行一次动作,其他游戏都选择4。这次的试验中所有的游戏都将这个参数选择为4。
- paper中提到了agent history length的值都选取为4,并且提到因为算法足够稳定,这个值选取为不同的值都是可以的(比如3或者5)。这个值选取为4表示在游戏过程中会记录最近4个观察到的画面,并且将这四个画面合并在一起作为模型的输入
- 各个参数的选择只是基于Pong, Breakout, Seaquest, Space Invaders和Beam Rider这几个游戏,他们没有花很多时间在参数的选择上,但是发现效果仍然很不错。
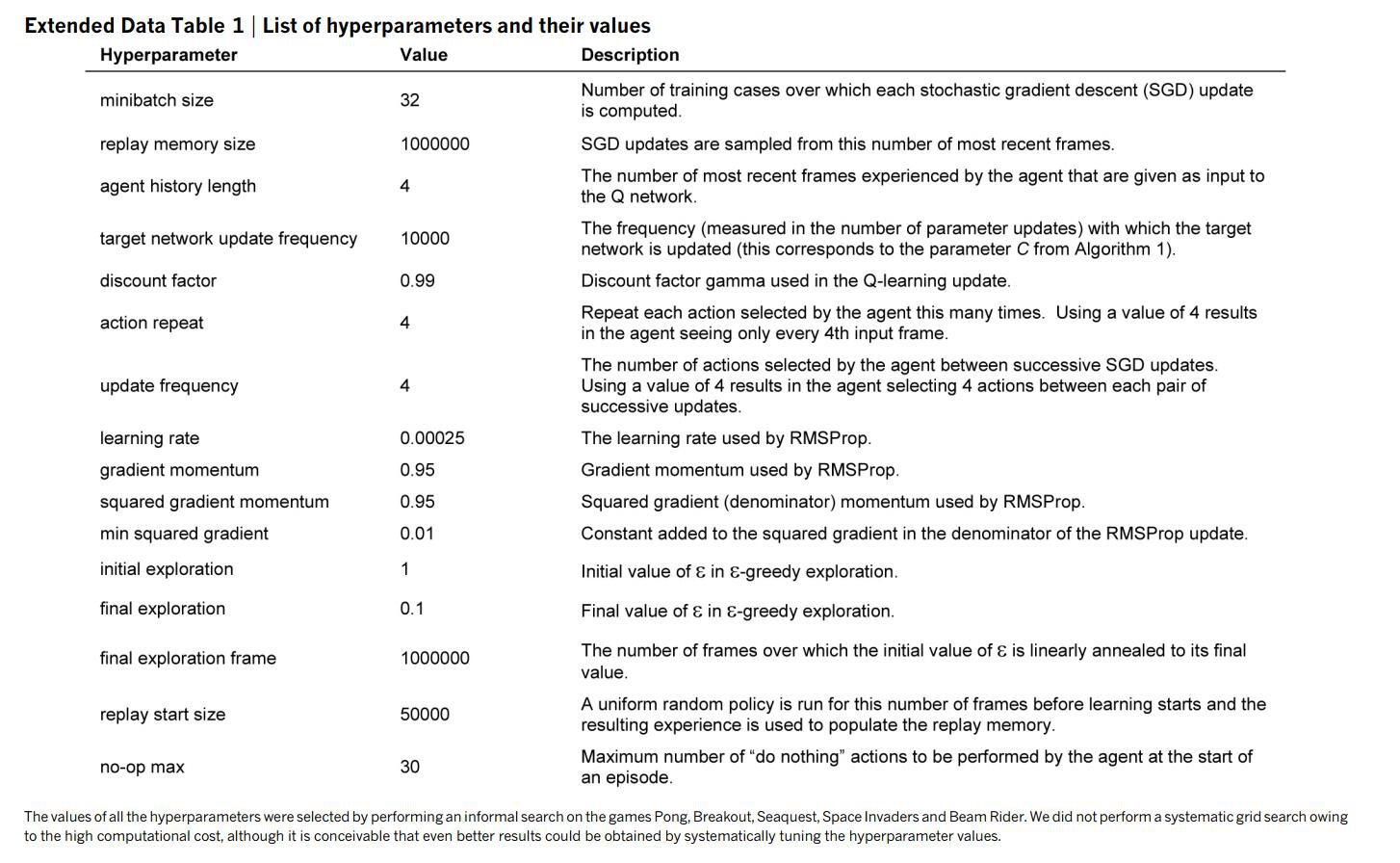
其他参数以及说明如下表所示:
结果分析
学习结果可视化
paper中使用一种叫做t-SNE的降维方法将学习到的东西展示在二维平面上,并对产生的结果进行分析。Space Invaders游戏结果如下图所示:
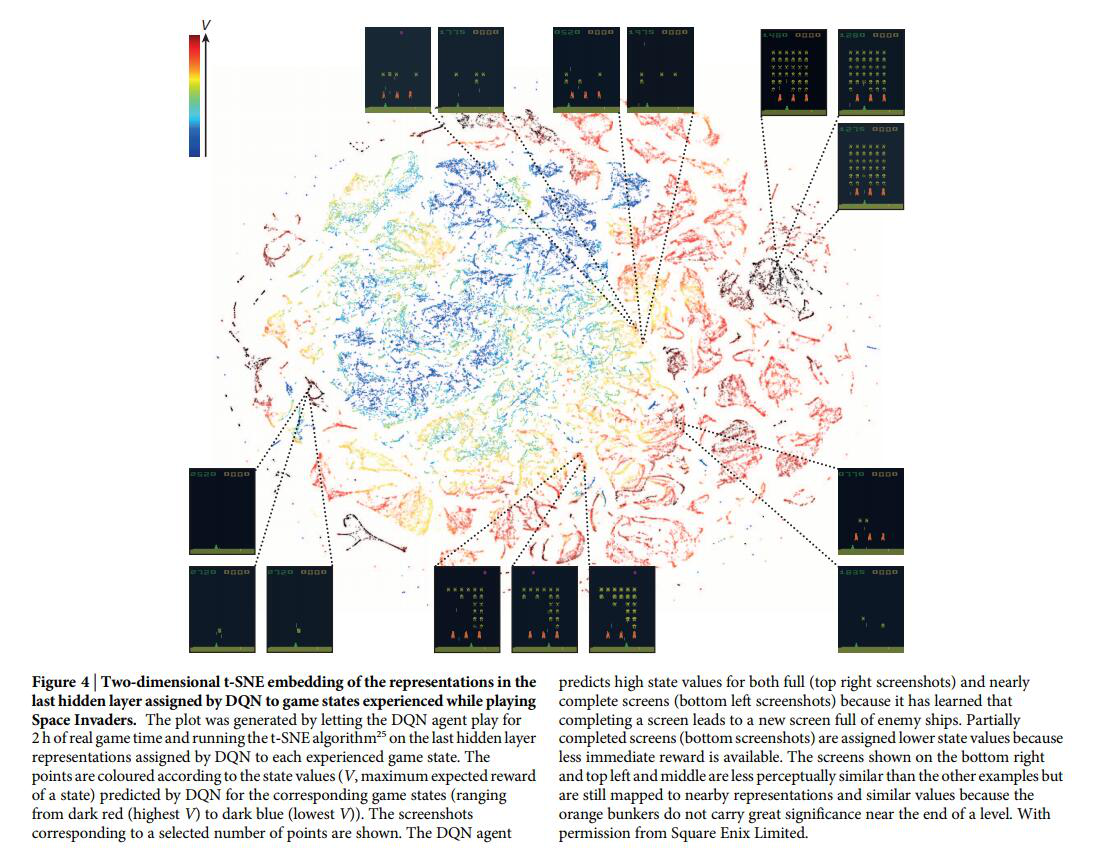
具体做法是将这个游戏两个小时的游戏画面喂给神经网络,提取最后一个隐藏层的feature,然后使用t-SNE进行降维展示在平面上。图案中的颜色表示对这个状态的估值,估值由高到低是从深红色到深蓝色。从这个图形中可以看出一些信息:
- 对于状态相近的游戏画面,神经网络给的估值也相似,压缩后点的位置也很相近
- 网络还学到了不同时刻游戏中橘黄色掩体的重要性是不一样的。上图中给了三组除了有无掩体外其他状态比较相近的图,这三组图中的状态估值很接近(与其他时刻有无掩体比较),然而其实他们的状态差距有点大,这个原因就是已经到了游戏末期,掩体已经不是很重要了,有没有掩体对于状态的评估影响不大。
- 左下角(游戏即将结束)和右上角的图(游戏刚刚开始)估值接近并且都很大。是因为网络已经学到了在游戏结束后会立刻开始一个新的游戏(左下角的状态很容易切换到右上角的状态),而消除了一部分敌人的游戏画面估值不太高是因为这时候剩余的reward已经没有很多了。
- 在paper的Extended Data 图一中,作者还比较了人类玩家不同时候的画面截图,以及AI自身游戏过程中的截图,用同样的方式喂给神经网络然后降维分析,发现网络没有区分人类玩家和AI玩家,对类似画面的估值是一样的,说明DQN确实是通过游戏数据生成的Q值,而不是自身产生的Q值。
对不同游戏类型的分析
对不不同类型的游戏,DQN表现出的结果也不太一样,通过实验发现,DQN比较擅长于需要相对长时间策略的游戏。比如打砖块(Breakout),AI在游戏中学到了尽量在墙边打通一条通往顶部的路,这样球就会有很大的几率在上面自己碰撞消灭砖块而不需要玩家移动挡板,这个视频中展示了学到这个策略的效果。然而对于需要一些规划的游戏(比如Montezuma’s revenge),这种方式的实作效果不是很好,这个游戏中需要玩家先去找到钥匙然后开启大门过关,但是AI并没有学会这个逻辑。
Q值的可视化以及实际意义分析
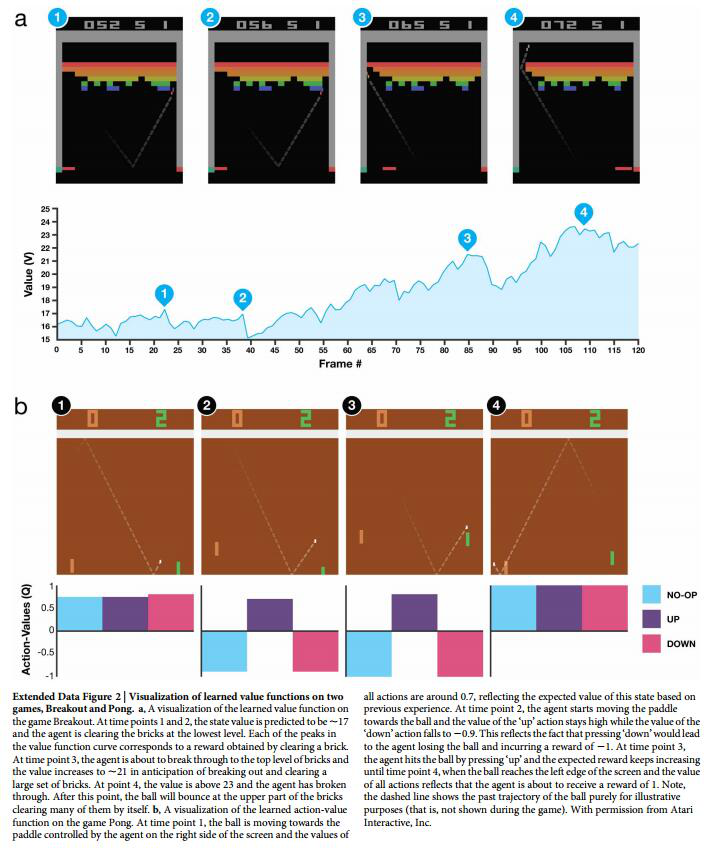
这个图中分析了Q值直观上代表的意义
图a中的1和2都是快要打到砖块了,由于打到砖块会有一个reward,这两个状态的Q值都会有一个小的上升,在清除砖块之后,由于reward已经得到,距离下一个reward又有段距离,所以接下来的状态Q值急剧下降。到图3的时候由于快要打通一个到顶部的通道了,所以3这个点的Q值很高。图4的时候已经打通了这个通道,小球可以在上面不停的消除砖块而不需要玩家操控,神经网络给4这个状态一个很高的估值,并且这个值能持续一段时间。
图b是AI玩Pong游戏的分析,一开始图1的时候,由于小球距离拍子还有段距离,所以是否移动都无所谓,这时候三个状态的估值近似。图2和图3的时候只有向上移动才能打到球,否则会输掉游戏导致负的reward,所以这两个状态下,向上的这个动作估值最高,其他动作都会有负的估值。图4中虽然马上会得到一分,但是与玩家选择哪个动作无关,所以这时候三个动作的估值仍然很相近。
参考
- Human-level control through deep reinforcement learning
- Human-level control through deep reinforcement learning - Presented by Bowen Xu
- Nature : Human-level control through deep reinforcement learning - Youtube
- Deep Q network learning to play Seaquest - Youtube
- 用于降维可视化的t-SNE
- What is the Best Multi-Stage Architecture for object Recognition
- Google DeepMind’s Deep Q-learning playing Atari Breakout - Youtube