

关于
之前刚接触机器学习的时候一直想用项目来练手,最初想到的就是交大单一入口的验证码,印象中似乎是在吴恩达的机器学习这门线上课程快结束的时候就着手开始写这个项目了。中间断断续续写了一下就放弃了,主要是在于没有什么图像处理的经验,并且数据量太小(当时只想到了自己标记这一个方法)。
后来这个学期,程式设计课程有个同学想做一个跟我之前想法几乎一样的东西,要实现单一入口的自动登录,我就顺便把这个项目完善了一下,顺便记录中间遇到的困难和解决的思路。
第一次从无到有弄出一个项目还是蛮有成就感的(虽然技术难度几乎是没有),但是深刻认识到深度学习领域目前距离端到端(end-to-end)的成果还有很长的路。这次的主要时间都花在怎么拿到标记过的数据和切割验证码了,真正跟深度学习有关的内容很少。
训练集来源
整个过程中访问了这个网站很多次,造成了蛮多不必要的访问量,感到很抱歉,同时也非常感谢至今没有被封IP,所以之前下载图片的代码就不放上来了(并且后面找到了方法不需要从这个网站下载图片),希望大家也不要轻易去暴力下载图片,我会放上已经标记好的数据供大家使用(后面会说明这些数据的来源)。
下载地址:
了解单一入口验证码
一开始的思路是想自己下载很多张验证码图片,然后手动标记的。然后初步观察了一下,这个网站的验证码:

可以看出验证码分为下面这四种:
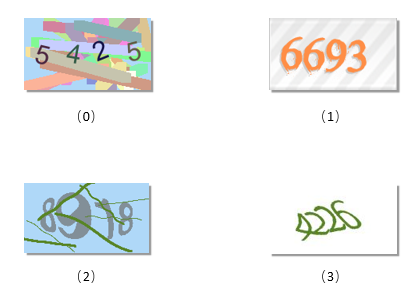
由于四种验证码分割来看的话每个数字之间的差别还是有点大,并且真正开始写的时候时间不是很充足,所以为了保险起见使用了四个不同的网络来分开处理。针对每种验证码需要考虑的有两个问题,数据从哪来以及怎么将一张图片切成四个小图片来进行预测。
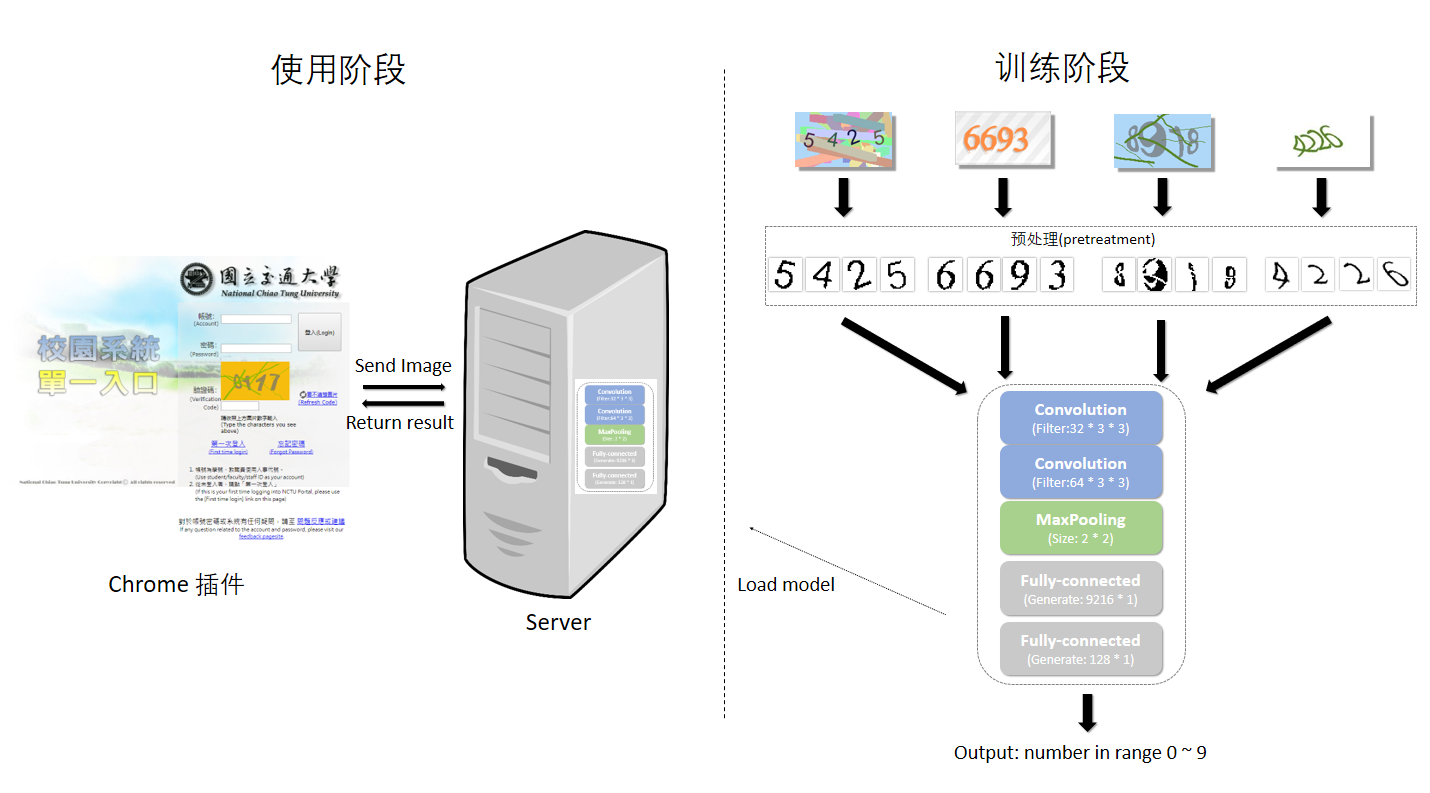
整体思路
做一个chrome插件,在单一入口界面拿到验证码post到server端,拿到返回的识别结果填到对应的input框中
示意图如下:
代码结构
- data
- labeled (按照类别放置标记过的验证码)
- single_letters (按照类别放置切割之后的图片,可以作为神经网络的输入)
- unlabeled (放置从网站下载没有标记的图片(后来发现已经不需要了))
- model (放置训练好的模型)
- templates (Flask模板,之前手动标记图片的时候用到的,后来已经不需要了)
- extract_letters.py (将图片分割成能喂给CNN的data)
- helper.py (主要是图像预处理的代码,包含怎么分割每种验证码)
- label_img.py (架设server的代码,之前用来标记图片,后面用来加载模型预测也用的这个)
- predict.py (输入图片,输出预测结果)
- train_model.py (训练模型)
CNN架构
由于我对架构的设计还没什么头绪,所以在网上找了个MNIST的架构(来源已经忘记了,有人知道的话希望能提醒我补充reference)
目前使用的是Keras,示意图如下:

每张图片经过预处理后切成四张 28 * 28 的小图片,然后分别喂给这个网络,输出结果按照顺序拼起来就是对应图片的识别结果。
对于预处理结果不是四张图片的情况直接返回错误信息。
运行
1. 下载数据
下载地址:
解压放到labeled文件夹
2. 分割图片
执行extract_letters分割图片
注意将captcha_type替换成0到3的数字
python extract_letters.py {captcha_type}
这时候 data\single_letters\ {captcha_type} 文件夹中应该有分割好了的图片,大小都是 28 * 28
3. 训练神经网络
一般训练5个epoch准确率就还不错,也可以尝试多训练几个epoch
python train_model.py {captcha_type}
4. 验证码识别
本地图片识别
这部分captcha_type是可选参数
usage: predict.py [-h] [–captcha_type CAPTCHA_TYPE] image_path
e.g.
python predict.py data\labeled\1\6693.jpg --captcha_type=1
使用server
本地使用flask架server
python label_img.py
浏览器端post图片的base64编码到服务器
function post_image(){
// image to base64
var img = document.getElementById("captcha");
var c = document.createElement('canvas');
c.width = img.width;
c.height = img.height;
var ctx = c.getContext('2d');
ctx.drawImage(img, 0, 0);
var base64String = c.toDataURL();
$.ajax({
method: 'POST',
// 这里必须是https,chrome不允许https到http的请求
// 其他浏览器没有验证
url : "https://localhost:5000/predict",
data : {
image: base64String
},
success: function(data, status){
$("#seccode").val(data);
}
});
}
后续
这四种验证码目前只处理了前面三种,最后一个还没有好的思路
其实前面的两种验证码可能都不太需要用上机器学习的方法,第一种背景去除的好的话其实很规则,第二种会发现相同数字只会出现一种形态(就是所有的1都相同,所有的2都相同…)
后面两种验证码重复率特别高,下面两幅图是之前手动标记的验证码的截图:


最后一种验证码重复的实在是太多了,就没有用红框框起来。
剩下一点想说的
- 验证码处理过程中其实有很多思路,实际操作比想的要困难一点,有时候从思路到具体的代码会经历好几个小时,并且结果不一定很好。
- 平常接触的东西都偏向于研究,但是实际到应用阶段非常需要工程能力,刚开始数据处理的时候一点头绪都没有,都不知道图片要怎么作为input喂给神经网络。
- 验证码现在已经有很多类型的了,比较难处理的是重叠的很多的(不确定能不能用Hinton的Capsules来解,如果能解开的话之后做验证码可能都需要换一个思路了