

摘要
Page-based virtual memory能提高程序员的效率、代码安全性和内存的使用率等好处。现在的系统基本都使用了虚拟内存(virtual memory)这个技术,做法一般是有一个表格记录了虚拟地址(virtual address)和物理地址(physical address)的一一映射,这个表格叫做分页表(page table),但是由于每次需要物理地址都在page table中查找会很慢,所以有TLBs(Translation Lookaside Buffers)来加速这个查找过程,这个东西本质上是一个硬体(hardware)的缓存(cache),把一些page table中的内容放在TLB中,每次查找的时候先在TLB中进行查找,找不到再去page table中查找。这个做法能加快物理地址获取的速度,然而现在存在的问题是如果TLB中没有找到,遍历page table的时间仍然会比较长,造成平均获取物理地址的时间开销还是比较大。所以这边paper就结合之前的一些研究提出一种改进方法,目标在于减少获取物理地址的平均时间。
虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。与没有使用虚拟内存技术的系统相比,使用这种技术的系统使得大型程序的编写变得更容易,对真正的物理内存(例如RAM)的使用也更有效率。
相关研究
这篇paper之前就有些相关研究做了类似的事情,大概可以分成三类:
0. Page-based Translation
最原始的做法,在TLB中记录虚拟地址到物理地址的一一映射,找不到的时候就去page table中查找
1. Multipage Mapping
这种方式是多对多的映射,一个TLB对应多条page table中的记录,查找的时候先找到一个地址区间,然后再在这个地址区间中找到这个虚拟地址对应到的精确的物理地址,其中的实作细节之前的paper有自己的做法。这种做法的好处在于在相同TLB实体数量的情况下,能覆盖到更多的地址范围。但是这个做法也有一些缺点,作者的说法是要求size alignment(具体这个不确定是什么意思,可能是说一个TLB实体映射8个page的话,这个系统中其他的TLB都要映射8个page,这个限制就有点死板。由于没有看引用的paper,所以不确定表示的是不是这个意思。)并且这种方式下TLB的覆盖率远远不能满足现在的大内存系统。
2. Large Pages
这种方式下有点类似于上面,区别在于上面的做法一个TLB实体对应一般是8到16个page,这里映射的地址更大些,在x86-64架构下是2MB和1GB的page size(之前paper中提到的两种做法)。这个的优势在于能覆盖更多的page,但是缺陷是跟上面类似要求size alignment。
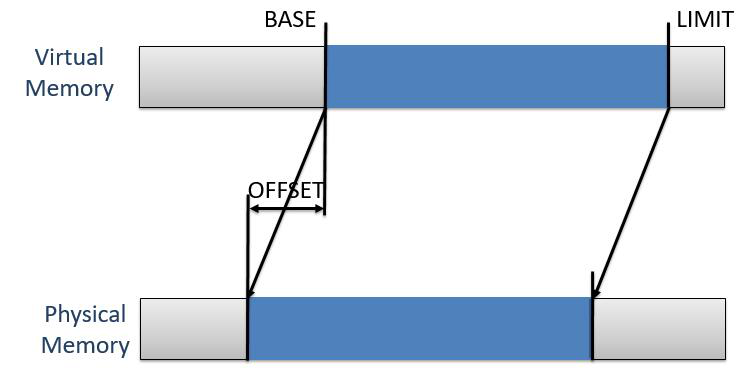
3. Direct Segments
这个做法采取了另外一种思路来加速一大块虚拟内存到一大块物理内存的查找速度。这个做法的思路是有一个(BASE, LIMIT)到OFFSET的映射,如果一个虚拟地址在BASE到LIMIT之间的话,根据OFFECT就可以算出这个虚拟地址对应的物理地址,并且这个计算不需要有遍历的过程,所以获取物理地址的速度会比较快。这个做法的优势在于没有地址大小的限制,但是之前的paper提到一个应用程序只能使用一个Direct Segments,并且这个实作细节对应用程序不透明(个人感觉不透明是正常的做法,我觉得程序员分配内存的时候应该只声明大小就行了,具体分配在哪应该是编译器或者OS做的事情。虽然这样编译器没有办法最优化内存分配,但是感觉权衡程序运行速度和程序员开发速度等细节,我感觉我还是愿意内存分配的细节对程序员隐藏)
对比
以上的每种都有自己的适用范围,作者在paper中进行了对比:

最左边是各种做法,其中第二排和第三排都是Large Pages这一类,最下面的Redundant Memory Mapping是作者提出来的做法
Redundant Memory Mappings
这个是作者结合上面说到的三类方法总结出来的想法,简单来说就是结合了第三种(3. Direct Segments)和原始的做法(0. Page-based Translation),并且把第三种改良成了一个应用程序可以使用多个range translation。当多个page挨在一起的时候就用range translation来表示,其他的用原始的TLB来表示。
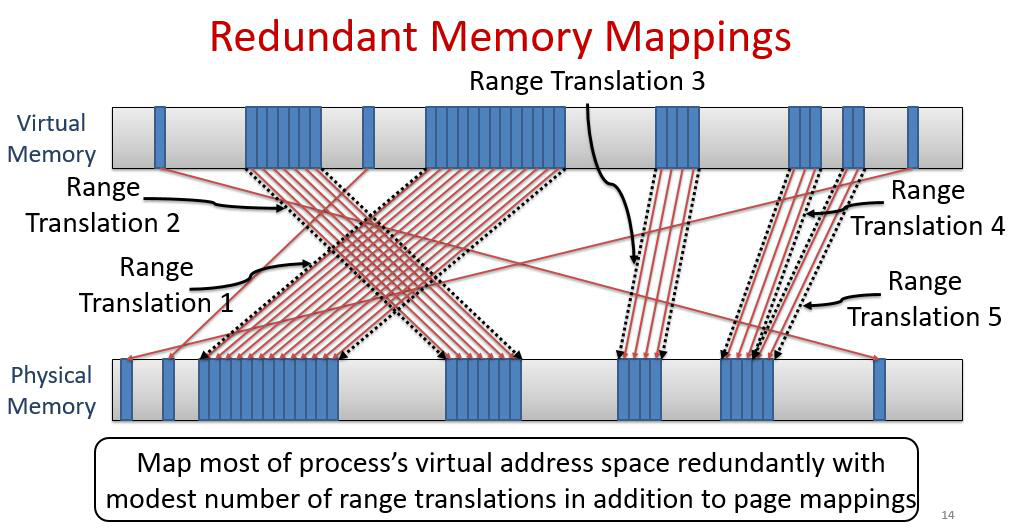
具体在硬件的架构上,修改原始的缓存结构,修改前后对比如下图:
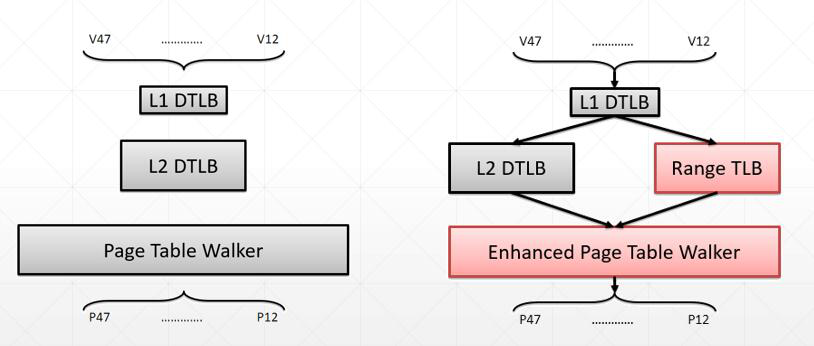
图的左边是说之前的硬件架构下,当查找虚拟地址对应的物理地址的时候,如果L1层的TLB没有查到就去L2查,L2没有查到就遍历整个page table。然后作者的想法是应该要像右边这样,在L2层增加一个Range TLB,一开始还是和之前一样去L1里面查找,在没有找到的情况下同时在L2和Range TLB中查找。只要一个查找到了结果就会返回这个结果并且重写L1中的内容,只有在两个都没有查到的情况下才会遍历page table,并且这个page table是经过改良之后的遍历方式,具体在实作的部分会介绍。
架构上的支持和系统层面的支持
Range TLB
range TLB的设计基本上可以用这个图直观的表现:
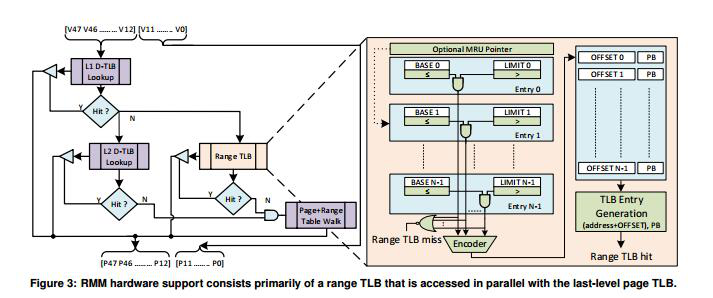
右边就是设计的细节,在range TLB中的查找是对比一个个的BASE和LIMIT,判断当前要查找的地址是否在一个range translation中,如果查到了就会计算需要的物理地址并且返回(paper提到的是根据BASE和LIMIT返回OFFSET和Protection),如果没有查到就告诉上一层miss了
为了加快range TLB中的查找速度,那里面采用了一个叫做MRU的策略,MRU Pointer储存了most-recently-used range translation,感觉是最近一段时间内使用的最多的才提到最前面,而LRU是最近使用的就在最前面。作者说这样能减少Range TLB中查找的时间
管理range translations
这部分的paper其实没有太看懂,由于作者想达到的效果是在目前的架构上做很小的改动达到提高速度的效果,所以没有改变之前的L1、L2的整体设计(其实好像是在protected bit中增加了一些信息),就是说在作者设想的这个架构里面,去掉作者增加的这两个部分,整个系统也是可以正常运转的(就和现在一样),只是加上作者的这两个改进后效果会更好,简单来讲就是作者增加的这部分其实都是冗余的信息,增加了能达到更好的效果,没有增加就和目前的架构一样。
由于之前的东西都没有改变,所以只需要管理range translation里面记录的内容就好了。我理解的意思是在后台一直会扫描有哪些地址被使用了,如果有连续的地址被使用就给这个page里面一个bit记录这个信息,同时把这个page加到range translation中,修改对应的BASE或者LIMIT,这样下次就能在range TLB中的查找获取这个地址了。
作者设想在OS层面增加一个数据结构,类似于树一样,只是这里是用来查找Range Table,仔细的算法好像还比较好理解,但是作者在实作的时候只使用一个list来代替了,理由是他们Demo的系统中range translation比较少,他们使用的是32个实体。认为这个大小用list的速度已经比较快了,如果用前面提到的数据结构会更快,但是在这里没什么必要。
实作和结果
介绍
整个实验环境的配置在这个图中:

OS层面有一些改动。
然后range Table没有实作出来,而是使用一个Inter x86-64的core来表示的这个部分,并且这个部分的查找跟L2的查找并没有像之前强调的那样使用同时进行,而是等L2 miss之后再在range TLB中查找。所以实验结果中没有改进前后整体效能的比较结果,而是从下面三个方面对结果进行了分析:
由于page-walks导致的执行时间开销
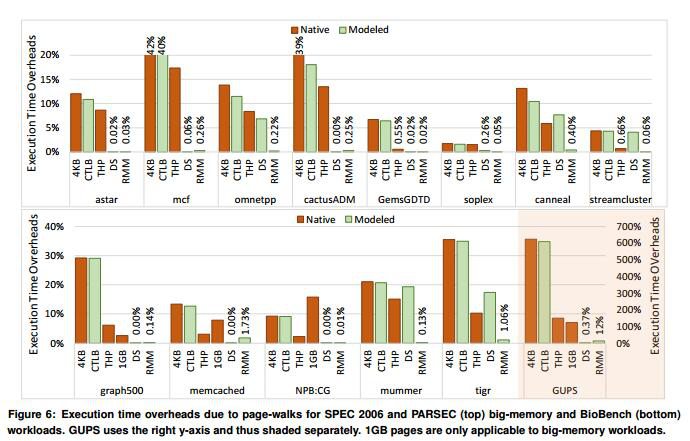
对比了不同workload上,花费在page-walk上的时间。这里对比的不是总体的时间(前面也说过由于没有达到预期的L2和range TLB并行查找,做出的总体时间对比也没有说服力)。从这里可以看出来除了与Direct segments这种方式对比之外,RMM对所有的workload都表现良好,并且有较大的改进。就算是跟Direct segments比起来差一些的workload,差距也没有很大。说明在page-walk上的改进是很成功的。
miss比例和TLB entry数量的关系
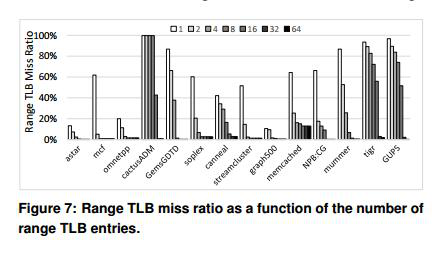
这个图说明一般来说在TLB实体数量小的时候,Range TLB查找的时候miss的比例会比较高。说明目前大部分程序要求多个range table实体,尤其是大的working sets。
个人感觉应该是现在对内存的需求量很大,随着用完回收之类的做法导致运行一段时间后内存的分配并不连续,所以range translation的做法在这里起到的作用就不是很大,导致range TLB miss。
Demand Paging和Eager Paging的对比
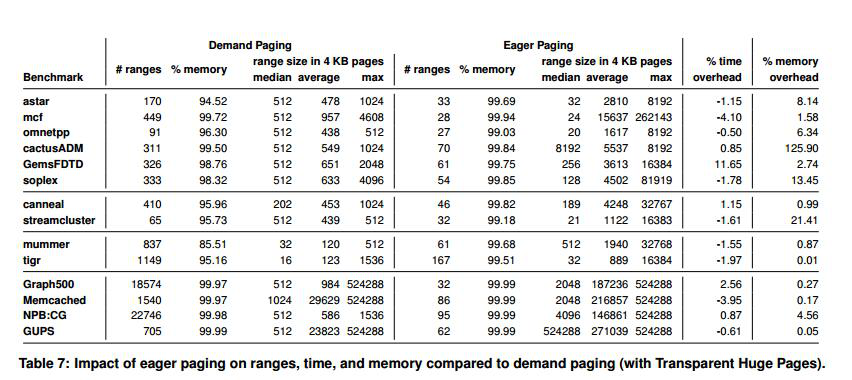
Eager Paging的做法是在申请虚拟内存的时候就直接分配出去物理内存,而Demand Paging是真正用到这个内存(读或者写)的时候才分配物理内存。作者比较这两个性能区别的原因是在系统层面分配内存的时候有一个伪代码说明了一些细节(我没仔细看这个代码所以前面就没提到)。然后实作的结果是时间上的开销基本上没有什么很大的区别,但是内存的额外开销Eager Paging这种方式就要严重一些。
后面的篇幅还提到了用电量的说明什么的,没仔细看
讨论
作者在paper的第六部分有一些讨论,一些在实作的时候应该要考虑的事情。
大概有四点:
- TLB friendly workloads:有些workload其实对现有的架构已经做了些适应,这个时候用原有的架构就已经效果不错了,加上作者提出的这儿冗余机制反而会拖慢速度,所以作者说以后可以加上一个开关来视情况是否要开启range TLB
- Accessed & Dirty bits: 缓存到range TLB中的内容应该会有一些机制考虑是否在L2中已经改过了。因为这个架构是一个冗余的机制,所以可能在这里的内容在L2中也可能有,但是由于没有修改之前的整个结构,会写的时候只会更改L2中的内容(因为之前的架构里面根本没有range TLB,回写机制根本就不会更新Range TLB),这时候range TLB中的内容可能就是有问题的,如果刚好下次获取信息的时候是从range TLB中获取,这时候得到的就是错误的数据。在这个实验里面作者是没有考虑这种情况,也没有提出解决途径,但是这个是必须要考虑的一个问题。
- Copy-on-write:这个就与大家都熟悉的copy-on-write做法是一样的,修改range TLB中的内容,没必要马上就去改实际的内容,因为在频繁修改缓存内容的时候,如果每次都回写实际内容,会有很大的性能损失。所以有人提出来,反正都是下次还是在缓存里面读的,真正内容是哪个版本的根本就不重要,只要在缓存里面被替换的时候在写到真实的page table里面就好了,这样又快又不会造成错误数据。作者认为这里应该也要用这种技术。
- Fragmentation: 如果一个workload分配到的内存都是不连续的,这时候显然作者的想法就不太靠谱了,所以这个情况应该要禁用range TLB。