

Protobuf编码分析
前面对比了 PB 编码和自己手写一个编码的速度,其中有个地方感觉有点奇怪:自己写的编码和 Protobuf 编码(下面简称 PB 编码)处理后的二进制长度居然相同。其实我这里写的有点小问题,就是编码后是无法正常解码的。常规操作是编码的一方需要告诉解码的那边,每个字段的长度,如果是定长的字段,比如特定的整型等,编码方和解码方提前可以约定好,就在编码结果中可以省略,但是对于字符串这种不定长的字段,就需要编码的时候给个字段长度的描述或者结束标记,要不然解码的那边会不清楚解析这个字段需要截取多长的字节。
这次就详细看下 PB 编码后的内容是个什么格式
字符串编码
先从简单的字符串编码开始看起,这部分也介绍下具体的研究方法
首先定义一个Proto文件
syntax = "proto2";
package testData;
message Test1 {
required string s1 = 1;
}
实验中要做的就是给 s1 设置不同的值,看编码出来的结果中能不能找到什么规律。
这里先定义一些工具函数,首先是 PB 转 JSON 字符串和一个打印 PB 的函数:
string PbToJson(const google::protobuf::Message &pb) {
string jsonStr;
google::protobuf::util::MessageToJsonString(pb, &jsonStr);
return jsonStr;
}
void encodeAndShow(const google::protobuf::Message &message) {
size_t size = message.ByteSizeLong();
char *buffer = new char[size];
message.SerializeToArray(buffer, size);
cout << "====================================" << endl;
cout << "pb: " << PbToJson(message) << "\t size: " << size << endl;
debugPrint(buffer, size);
cout << "====================================" << endl << endl;
}
其次我们要将二进制用不同方式打印出来,这里定义三种表示方式,方便调试过程中按需显示
enum PrintFlag {
PrintFlagBin = 1,
PrintFlagHex = 2,
PrintFlagChar = 4
};
// 默认显示所有方式
int g_printFlag = PrintFlagBin | PrintFlagHex | PrintFlagChar;
static const char g_asciiChar[129] =
"................"
"................"
" !\"#$%&,()*+,-./"
"0123456789:;<=>?"
"@ABCDEFGHIJKLMNO"
"PQRSTUVWXYZ[\\]^_"
"`abcdefghijklmno"
"pqrstuvwxyz{|}`.";
void debugPrint(const char *buffer, size_t size) {
static const int nBatchSize = 8;
size_t index = 0;
while (index < size) {
// 二进制显示
if (g_printFlag & PrintFlagBin) {
int remain = 0;
for (int i = 0; i < nBatchSize; i++) {
if (index + i >= size) {
remain = index + nBatchSize - size;
break;
}
unsigned char* address = (unsigned char*) (buffer + index + i);
for (int j = 7; j >= 0; j--) {
unsigned char byte = (*address >> j) & 1;
printf("%u", byte);
}
printf(" ");
}
while (remain-- > 0) {
printf(" ");
}
printf(" ");
}
// 十六进制显示
if (g_printFlag & PrintFlagHex) {
int remain = 0;
for (int i = 0; i < nBatchSize; i++) {
if (index + i >= size) {
remain = index + nBatchSize - size;
break;
}
unsigned char* address = (unsigned char*) (buffer + index + i);
printf("%.2X ", *address);
}
while (remain-- > 0) {
printf(" ");
}
printf(" ");
}
// ascii码显示
if (g_printFlag & PrintFlagChar) {
for (int i = 0; i < nBatchSize; i++) {
if (index + i >= size) break;
unsigned char* address = (unsigned char*) (buffer + index + i);
printf("%c", g_asciiChar[*address]);
}
}
printf("\n");
index += nBatchSize;
}
}
然后给 s1 设置不同的值看编码结果:
void test1() {
testData::Test1 test1;
test1.set_s1("");
encodeAndShow(test1);
test1.set_s1("abcd");
encodeAndShow(test1);
test1.set_s1("AAAAAAAA");
encodeAndShow(test1);
}
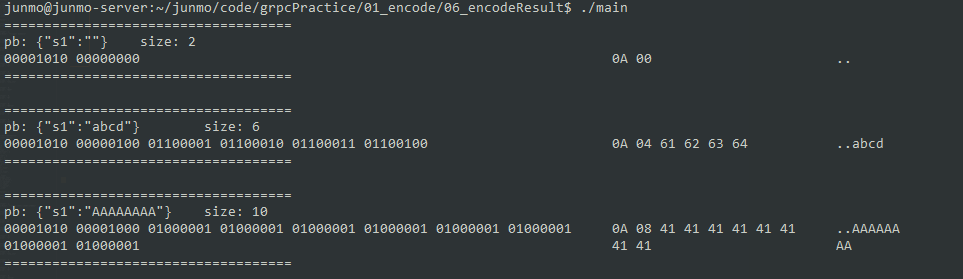
比较清晰的是第二个字节表示的是 s1 的长度,后面跟着的就是 s1 编码后的结果。
但是最前面的一个字节 0A 还不能确定是啥,猜测是类型或者 PB 本身的版本号之类的东西,留到后面看下
数字编码
message Test2 {
required uint32 i1 = 1;
}
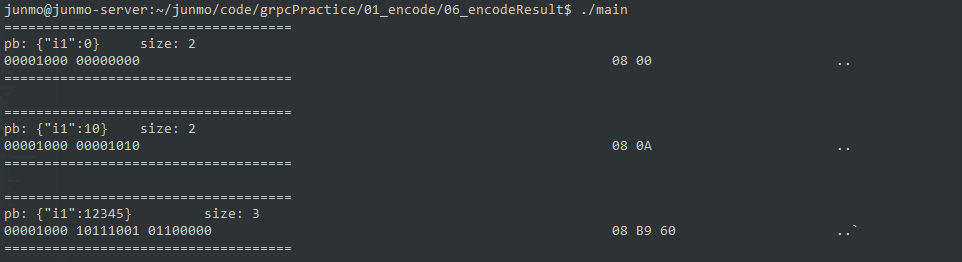
这里的结果比较有意思,原本我以为 PB 编码为二进制是定长的,也就是一个 u32_t 应该要编码为 4 个字节,现在来看跟被编码的值有关
再多尝试几个例子看下字节序以及编码的方式
test2.set_i1(0xFFFFFFFF);encodeAndShow(test2);
test2.set_i1(0xFFEECC88);encodeAndShow(test2);
test2.set_i1(0b11110000);encodeAndShow(test2);
test2.set_i1(0b00001111);encodeAndShow(test2);
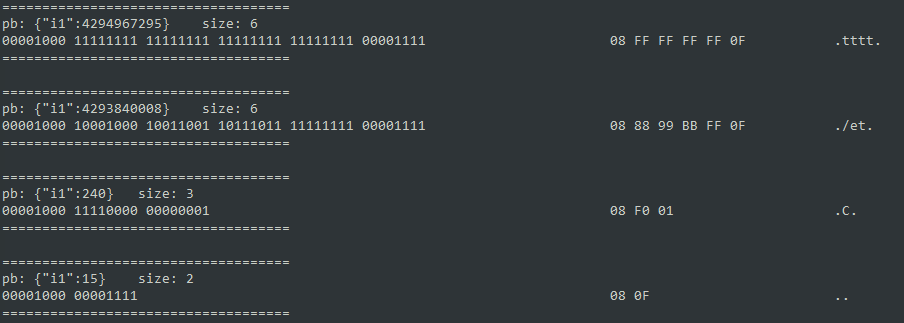
可以发现一些规律
- 应该是有些标志位之类的东西,会占用一些 bit,让编码后的内容比之前更长了
- 不同字节的顺序是低位先编码,高位有值的话编码在后面
- 同一个字节内部的bit顺序与编码前一致
更多的结论需要其他的一些尝试,不过好在文档里面其实有写内部是怎么做的:https://developers.google.com/protocol-buffers/docs/encoding
大概是每个字节内部最高位表示后续是否还有值,然后字节按从低到高依次排列。
以 0xFFEECC88 这个值为例,编码过程如下:

可以看到跟最终 PB 转二进制编码结果 10001000 10011001 10111011 11111111 00001111 相同
定长和不定长
定长的处理就比较符合直觉了,因为有固定的长度,所以可以省略掉前面的标识位,直接看几个例子,编码后的结果就是对应数字的二进制表示,跟不定长数字一样,也是低位在前,高位在后:
message Test3 {
required fixed64 fi1 = 1;
}
void test3() {
testData::Test3 test3;
test3.set_fi1(0xFFFFFFFFFFFFFFFF);encodeAndShow(test3);
test3.set_fi1(0x0);encodeAndShow(test3);
test3.set_fi1(0xFF);encodeAndShow(test3);
test3.set_fi1(0xFF00CC);encodeAndShow(test3);
}
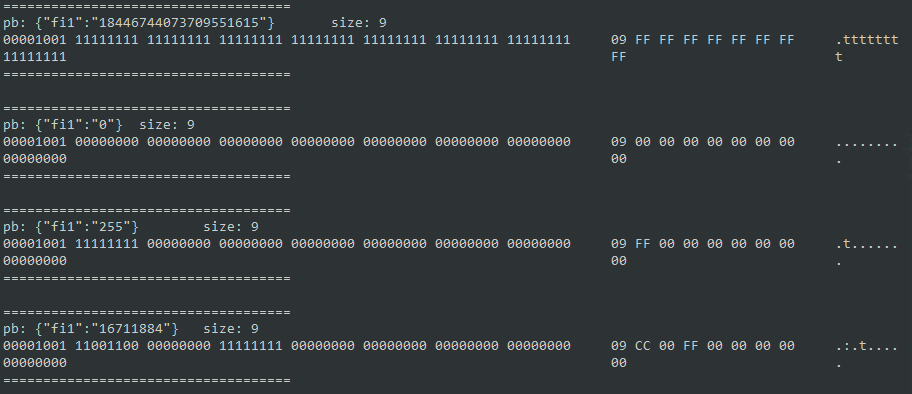
有符号和无符号
另一个例子看一下有符号和普通定长的 int 有啥区别,PB 里面有两种定长的数字类型 fixed64 和 sfixed64
message Test4 {
required fixed64 fi1 = 1;
required sfixed64 fi2 = 2;
}
void test4() {
testData::Test4 test4;
test4.set_fi1(0xFFFFFFFFFFFFFFFF);
test4.set_fi2(0xFFFFFFFFFFFFFFFF);
encodeAndShow(test4);
test4.set_fi1(0x1234567890ABCDEF);
test4.set_fi2(0x1234567890ABCDEF);
encodeAndShow(test4);
}
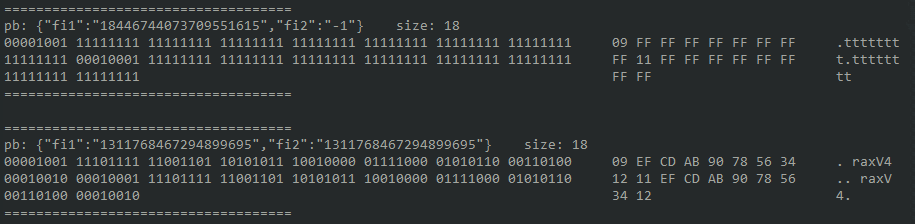
编码之后的东西看不出来区别,但是通过转json可以发现他们一个是有符号一个是无符号的
这个结论也可以通过 proto 生成的源码验证
uint64_t fi1() const;
int64_t fi2() const;
int32 / sint32 / uint32
Protobuf 中定义了几种整型 int32 / sint32 / uint32,尝试看下几种区别:
message Test5 {
required int32 i1 = 1;
required sint32 i2 = 2;
required uint32 i3 = 3;
}
void test5() {
testData::Test5 test5;
for (int i = 2; i >= -2; i--) {
test5.set_i1(i);
test5.set_i2(i);
test5.set_i3(i);
encodeAndShow(test5);
}
}
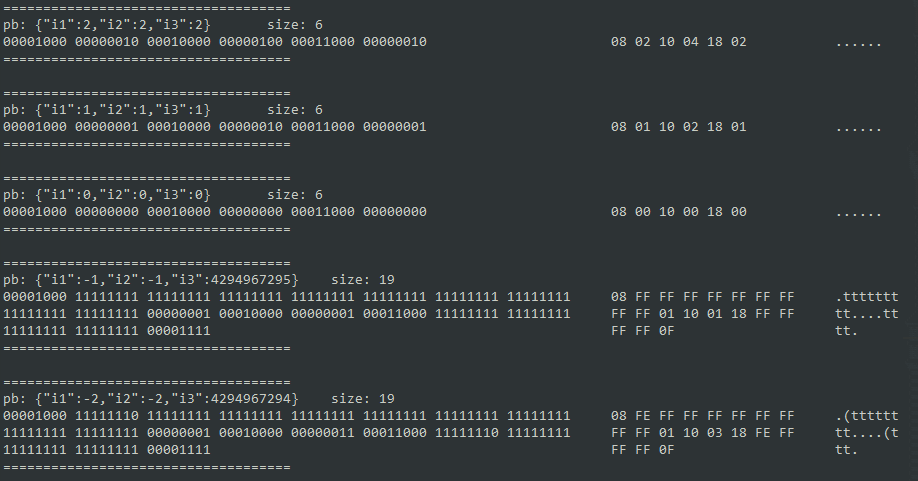
大致上可以推测类型编码分别是 0x08, 0x10, 0x18,后面就以这几个数字为分隔符看每个字段编码后的结果。
先看两个比较明确的 int32 和 uint32。在正数部分,int32 和 uint32 都符合直觉,是自身的二进制表示,大一点的数字会按照前面说明的不定长编码规律,1 个 bit 表示后面是否还有值,7 个 bit 表示编码内容。在负数部分,int32 将 -1 编码的内容变为了 int64,猜测是 protobuf C++ 的内部实现上用了相同的处理,并且这个编码结果只是加长了编码后的字节,解码后的结果不受影响。
在来看看 sint32 这个类型,这个也是有符号的整型,看他编码出来的内容
| 被编码的数字 | 编码后的内容 |
|---|---|
| 0 | 0x00 |
| -1 | 0x01 |
| 1 | 0x02 |
| -2 | 0x03 |
| 2 | 0x04 |
可以看出针对这种类型,使用了一种叫做 ZigZag 的编码方式,这种编码方式的好处也比较明显,当数字的绝对值较小的时候,可以将 PB 定义为这种类型,编码后的字节长度较小。
比较明显的例子就是 -1,int32 会编码出 10个字节,sint32 编码后只有 1 个字节,当数字一般比较小,但是又经常出现 -1 的时候,可以考虑这种类型。
double
double 在内存中是 8 字节,PB 里面的处理也比较简单,其实就是将对应字段 memcpy 复制到了 PB 内部的数据结构中,可以简单验证一下这个结论:
message Test6 {
required double d1 = 1;
}
vector<double> dTestCase = { 1, 123, 3.14159, -123, 0.001 };
for (double dTest : dTestCase) {
testData::Test6 test6;
test6.set_d1(dTest);
size_t size = test6.ByteSizeLong();
char *buffer = new char[size];
test6.SerializeToArray(buffer, size);
// 将原始的值在内存中的内容打印出来,跟PB编码后的部分(去掉类型)进行比较
cout << "====================================" << endl;
cout << "dTest" << dTest << endl;
cout << "PB encode: ";
debugPrint(buffer + 1, sizeof(double), PrintFlagBin | PrintFlagHex);
cout << "Data in memory: ";
debugPrint((char*)(&dTest), sizeof(double), PrintFlagBin | PrintFlagHex);
}
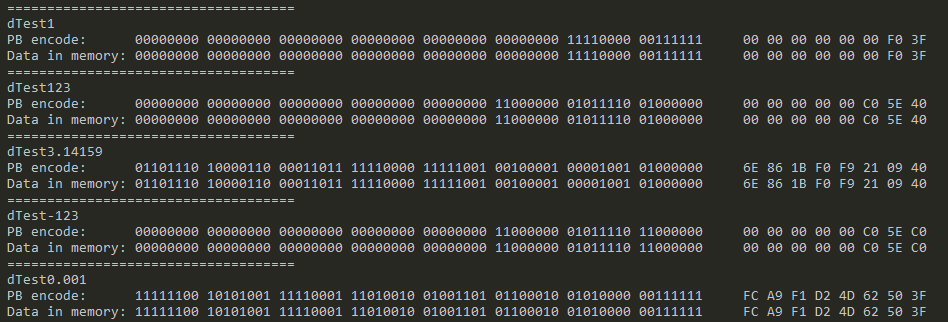
具体 double 用二进制表示的结果可以参考这个文章: 浮点数的二进制表示 - 阮一峰的网络日志
重复字段、可选字段、必须字段
先简单使用几个数字实验下 optional 字段是否设置值,repeated 字段不同长度的编码结果。
message Test7 {
required fixed32 requiredField = 1;
optional fixed32 optionalField = 2;
repeated fixed32 repeatedField = 3;
}
testData::Test7 test7;
test7.set_requiredfield(0xFFFFFFFF);
encodeAndShow(test7);
test7.set_optionalfield(0x00);
encodeAndShow(test7);
test7.add_repeatedfield(0x00);
encodeAndShow(test7);
test7.add_repeatedfield(0xFFFFFFFF);
encodeAndShow(test7);
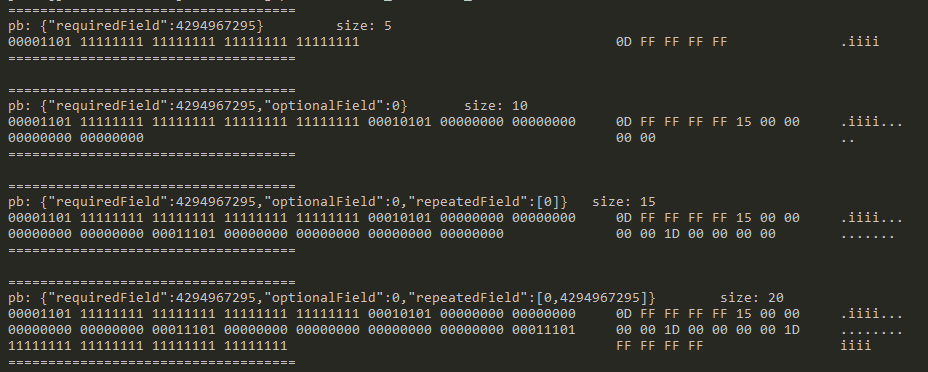
发现的规律是没有设置值,对应字段就不进行编码,这对于定义了很多字段,但是使用的时候只设置其中几个的场景是比较有效的。
不过这也引出来一个问题,之前我一直以为每个字段前面那个字节表示的是后面跟着的字段的类型,现在看来还包含 PB 里面定义的序号之类的,否则多个相同类型的 optional 字段,赋值其中一个,解码的时候会不清楚这个字段的位置在哪。
简单验证一下可以发现一些规律
message Test8 {
optional fixed32 i1 = 1;
optional fixed32 i2 = 2;
optional fixed32 i3 = 3;
required fixed32 i4 = 4;
required fixed32 i5 = 5;
}
testData::Test8 test8;
test8.set_i1(0xFF);
test8.set_i2(0xFF);
test8.set_i3(0xFF);
test8.set_i4(0xFF);
test8.set_i5(0xFF);
encodeAndShow(test8);

同样是 fixed32 类型,编码出来的字节是不一样的
大致可以看出来,前面 5bit 是序号,后面 3bit 是相同的。还是查看文档,发现确实是这个方式,PB 里面的类型没有很多,所以用 3bit 可以表示完。
| Type | Meaning | Used For |
|---|---|---|
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | fixed64, sfixed64, double |
| 2 | Length-delimited | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | groups (deprecated) |
| 4 | End group | groups (deprecated) |
| 5 | 32-bit | fixed32, sfixed32, float |
然后每个字段前面的字节就可以通过 (field_number << 3) | wire_type 得到。
有了这种表示之后,optional 和 required 字段其实编码之后没有分别,应该只是一种编码时候的防呆措施。repeated 字段每个里面都有一个字节用来表示 key,不过如果设置了 packed=true 之后就只有一个总的 key 字段,另外有一个字节用来表示后续字段的总长度。
总结
PB 编码后的内容不包含名称,使用索引定义到具体的字段。改变 message 或者字段的名称不影响编解码结果
大多数数字采用的是不定长编码,数字小的时候编码后的长度也会小;针对 int32 类型表示 -1 可能编码后会很大的情况,有 sint32 类型可以使用,如果数字的绝对值比较小,并且有时候会出现负数,可以考虑改用 sint32 代 int32。当数字的绝对值会比较大的时候,可以考虑使用定长数字 fixed32/fixed64/sfixed32/sfixed64 取代。
以上实验代码: code.zip