

我们平常的开发工作中,会使用到字符串、数字或者是自定义一些数据类型,然而在网络传输的过程中使用的都是字节流。因此在将这些数据从一台电脑发送到另一台电脑的时候,就需要一种方式将这些数据编码为字节流,接收方收到后将字节流解码为原始数据。这篇文章介绍了几种编解码(或者叫序列化/反序列化)的方式以及性能差异。
示例介绍
首先我们通过一个简单的例子来模拟这个场景
服务端:提供一个用户注册的功能,客户端传输姓名和年龄,返回现在系统用户总数和新注册的用户名称
客户端:发送新注册的用户名称和年龄给服务端
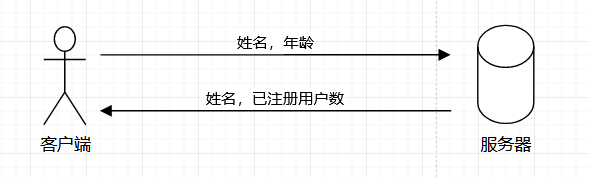
首先客户端需要将名字和年龄发送出去,一个比较简单的实现就是
void Register(string name, int age) {
int sock = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in servaddr;
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = inet_addr(IP);
servaddr.sin_port = htons(PORT);
connect(sock, (struct sockaddr*)&servaddr, sizeof(servaddr));
string sendMsg = name + "|" + to_string(age);
send(sock, sendMsg.c_str(), sendMsg.size(), 0);
// 省略后续逻辑
close(sock);
}
省略了部分代码,完整代码参考:code.zip
这里的实现只是将名字和年龄都用字符串表示,然后用 | 进行分隔,发送给服务端。
服务端接收之后,按照 | 分隔的方式解析出名字和年龄。然后处理注册部分的逻辑,返回总注册人数。
// 接收和解析部分代码,完整代码参照01_native/server.cpp部分
size_t recvSize = recv(client_sock, buffer, sizeof(buffer), 0);
buffer[recvSize] = 0;
string recvMsg(buffer);
cout << ">>> " << recvMsg << endl;
int splitIndex = recvMsg.find("|");
string name = recvMsg.substr(0, splitIndex);
int age = stoi(recvMsg.substr(splitIndex + 1));
这里简单来将完整示例中传输的信息打印出来看下传输的是什么内容:

图中
<<<表示发出去的内容;>>>表示接受到的内容;其他表示业务逻辑打印
可以发现要实现上面这些步骤,需要满足一些条件:
- 客户端和服务器要约定一种编码方式。这里是将所有字段都转成字符串,然后用竖线分隔
- 客户端和服务器需要知道每个字段的顺序。在这个例子中是名字在前,年龄在后。
这种方式很直观的就不太优雅,某天如果服务器解析数据的时候发现格式不对,很难排查是客户端编码的格式不对还是服务器的解码格式要更新了。
此外使用 | 分隔还有个问题,就是如果某天名字或者别的字段中包含这个分隔符号呢。当然也可以约定一些特殊规则处理这种情况,比如转义字符啥的,不过这就是另一个大坑了。
使用json
首先来处理分隔符的问题,其实有很多格式能够进行结构化的表达,比如 xml 或者 json。一般各种语言都会有一些比较优秀的第三方 json 库,比如我们这里用 nlohmann/json 这个库来进行编码和解码。使用这个 json 库比较简单,一种方式是直接下载 json.hpp 文件,然后引入对应头文件即可。
客户端和服务端部分代码修改为下面这样:
// 客户端发送部分编码
json sendJson;
sendJson["name"] = name;
sendJson["age"] = age;
string sendMsg = sendJson.dump();
send(sock, sendMsg.c_str(), sendMsg.size(), 0);
// 服务端接收部分解码
char buffer[BUFF_SIZE];
size_t recvSize = recv(client_sock, buffer, sizeof(buffer), 0);
buffer[recvSize] = 0;
string recvMsg(buffer);
cout << ">>> " << recvMsg << endl;
json jsonRecv = json::parse(recvMsg);
string name = jsonRecv["name"];
int age = jsonRecv["age"];
这里我们优雅的解决了某个字段可能会带有竖线的问题,并且对于字段的顺序也没有了要求,因为我们这里带上了字段的名称,可以通过名称定位到某个字段。
然而这样也带来了另一个问题:就是传输过程中带上了一些冗余的信息。
我们先看看使用 json 之后传输的内容

由于 json 有自身的语法规则,需要带上诸如 "",{} 之类的符号,还要有字段名称,但是这些东西我们完全可以在商定内容格式的时候一起商定好,而不需要传输过程中带上。
另外还有 json 格式编码效率的问题,虽然这个问题不同实现方式的效率会有些不同,但是一般来说 json 格式需要带上字段名和固定的符号,这就带来了额外的工作,也会有一定的性能影响。
使用protobuf
用固定的 | 分隔会导致难维护且不优雅,使用 json 又会带来额外的冗余传输问题,有没有一种方式能兼顾这两者呢,谷歌推出的 protobuf 是一个不错的选择。
关于 protobuf 的介绍可以看官方的文档: https://developers.google.com/protocol-buffers
简单来说他是一种数据编解码方式,类似于 json 但是更小更快。
C++ 版本使用之前需要先安装,可以参考官方的文档。
使用 protobuf 进行编码的话,首先需要定义好传输内容的格式。比如我们这里涉及到两个传输,1. 客户端往服务器发送名字和年龄,2. 服务器返回名字和注册的总人数。
以第一个传输内容为例,首先需要编写 cmdRegister.proto 文件
syntax = "proto2";
package cmdRegister;
message Request {
required string name = 1;
required int32 age = 2;
}
这里有个坑是package名字如果是叫 register,
.pb.cc文件会一直编译不过。不清楚是不是用到了特殊的名称,改成 cmdRegister 就规避了这个问题
然后使用安装后的 protoc 文件生成 cmdRegister.pb.cc 和 cmdRegister.pb.h 文件
目前文件结构是:
.
├── client.cpp
├── Makefile
├── proto
│ ├── cmdRegister.pb.cc
│ ├── cmdRegister.pb.h
│ └── cmdRegister.proto
└── server.cpp
客户端和服务端部分代码修改为下面这样:
// 客户端发送部分编码
cmdRegister::Request request;
request.set_name(name);
request.set_age(age);
string sendMsg = request.SerializeAsString();
send(sock, sendMsg.c_str(), sendMsg.size(), 0);
// 服务端接收部分解码
char buffer[BUFF_SIZE];
size_t recvSize = recv(client_sock, buffer, sizeof(buffer), 0);
buffer[recvSize] = 0;
string recvMsg(buffer);
cmdRegister::Request request;
request.ParseFromString(recvMsg);
string name = request.name();
int age = request.age();
protobuf 并不是文本方式编码,没法直接打印其中的内容,不过可以转成 json 然后打印出来,打印的结果与 json 方式编码是一样的。
性能对比
这部分我们比较下三种编码方式在性能和编码后字节流的长度方面的差异
编码的内容还是一个字符串和一个数字,返回编码后的内容和长度。具体来说就是针对每种编码方式实现类似如下的函数:
size_t TestXXX(const string &name, int age, char *buffer) {
// 具体编码实现,使用name和age入参,编码后的字节流写入buffer中
// 返回编码后字节流的长度
}
三种编码方式的实现
// 将字段都转成字符串然后用竖线分隔的方式
size_t TestNative(const string &name, int age, char *buffer) {
string encodeStr = name + "|" + to_string(age);
strcpy(buffer, encodeStr.c_str());
return encodeStr.size();
}
// 使用 json
size_t TestJson(const string &name, int age, char *buffer) {
json jsonObj;
jsonObj["name"] = name;
jsonObj["age"] = age;
string encodeStr = jsonObj.dump();
strcpy(buffer, encodeStr.c_str());
return encodeStr.size();
}
// 使用 protobuf
size_t TestProtobuf(const string &name, int age, char *buffer) {
cmdRegister::Request request;
request.set_name(name);
request.set_age(age);
size_t size = request.ByteSizeLong();
request.SerializeToArray(buffer, size);
return size;
}
另外我们使用一种基准进行比较:
size_t TestBin(const string &name, int age, char *buffer) {
size_t offset = 0;
size_t size = name.size();
memcpy(buffer + offset, name.c_str(), size);
offset += size;
size = sizeof(int);
memcpy(buffer + offset, &age, size);
offset += size;
return offset;
}
然后使用相同的入参调用这些方法同样的次数,可以大致统计出每种方式编码后的长度和所使用的时间
下面是每个方法调用 1000000 次所花费的时间,和每种编码方式的长度
TestBin: time span: 0.006279, size: 9
TestNative: time span: 0.130976, size: 8
TestJson: time span: 0.682273, size: 25
TestProtobuf: time span: 0.085463, size: 9
可以看出 TestBin 的方式最快,除此之外,protobuf 的方式比另外两种快很多。
| native | json | protobuf | |
|---|---|---|---|
| 扩展性 | 不容易扩展 | 容易扩展 | 容易扩展 |
| 性能 | 较高 | 低 | 最高 |
| 字段冗余 | 有分隔符冗余 | 有分隔符冗余和字段冗余 | 没有冗余 |
| 主要缺点 | 不太优雅 | 性能查、字段冗余 | C++ 上需要安装、有些字段会导致一些bug、默认值问题 |
总的来说,protobuf 采取了单独书写类似协议文档的方式,让客户端和服务端都明白字段的大小和顺序,从而减少了传输过程中的数据量。并且编码后的字节与平台和语言无关,提供了多种语言的 API 方便编码和解码,从而高效方便的在不同平台间传递信息。